
Dies ist das letzte Kapitel der Reihe “Der größte Blindfleck des AI Engineers”. Wenn du die anderen Artikel bereits gelesen hast, bist du hoffentlich schon desillusioniert, was den Aufwand nach einem GenAI-PoC angeht. In den Artikeln haben wir uns um folgende Themen gekümmert:
- Part 1 (Der Sicherheitskäfig): Wir haben das Networking und die Foundation beleuchtet. Dabei ging es darum, die GenAI-App sowie sensible Daten in einer VPC und Private Subnets zu isolieren, damit man nicht einfach direkt an die Container oder Datenbanken kommt (Voreinstellungen ≠ sicher!).
- Part 2 (Agent-Lifecycle & Observability): Hier sind wir tief in die Compute-Ebene eingetaucht. Wir haben gesehen, wie wir mit Docker und AWS ECS/Fargate eine serverlose Laufzeitumgebung schaffen und warum das Self-Hosting des Observability-Tools Langfuse v3 architektonisch anspruchsvoll, aber für den Projektfortschritt äußerst nützlich ist.
Zur Erinnerung: Der Use-Case war es, eine hochspezialisierte Extraktions-Engine für Tierarztrechnungen (PDFs) für den Kunden bereitzustellen. Dabei ging es um zwei Ebenen der Datenverarbeitung:
- Rechnungspositionen: Automatisches Auflisten und Kategorisieren von Leistungen (z. B. „Prävention“ bei Impfungen) sowie das Erfassen von Preisen und Steuersätzen.
- Metadaten: Das Auslesen allgemeiner Informationen wie Klinikdetails, Versichertendaten sowie spezifischer Tierinfos wie Name und Rasse.
Im letzten Kapitel der AI Architecture-Reihe widmen wir uns der vollständigen Architektur und besprechen alle zusammenhängende Komponenten: das Full Picture ✨!
Infrastruktur (the complete edition!)
In den letzten Parts habe ich darauf geachtet themenspezifisch einen reduzierten Ausschnitt von der Architektur zu zeigen. Da wir schon die meisten Komponenten besprochen haben und nur noch wenige dazu kommen, ist jetzt ein guter Zeitpunkt, um die vollständige production-ready Architektur zu zeigen.
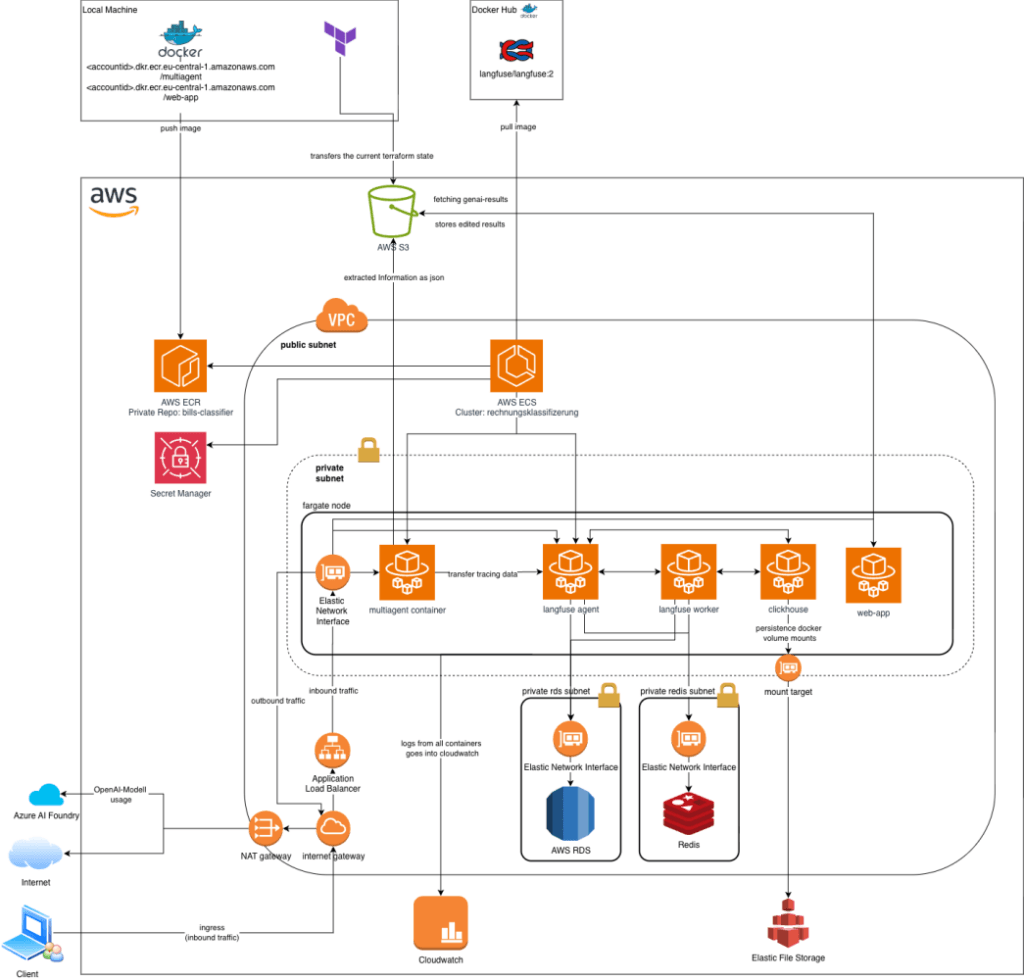
Die Vielzahl an Komponenten kann einen erstmal erschlagen, doch ich denke, durch die vorherigen Parts und Step-By-Step-Erläuterungen der einzelnen AWS-Services, finden wir uns jetzt schon viel besser im Komponenten-Dschungel zurecht. Das Einzige, was hier neu dazukam, ist die LLM-Integration, das Logging und der Client-Zugriff auf die Web-App. In diesem Artikel machen wir einen zusammenhängenden Komplettabriss und sind für das nächste produktionsreife Deployment besser gewappnet. Mit ein bisschen Transferleistung, kann man diese Architektur auch super in Azure übertragen (VNet statt VPC, ACR statt ECR, ACA statt ECS, Key Vault statt Secret Manager, usw.).
So, Endspurt!
Die Brücke nach Außen: LLM-Integration und Client-Zugriff
Ingress
Der Client adressiert zu Beginn den Loadbalancer (ALB) via URL/DNS. Hierzu passiert der Datenstrom zwingend das Internet Gateway, um in die VPC zu gelangen. Der ALB nimmt den HTTPS-Request entgegen und leitet ihn sicher via VPC-internes Routing an den Web-App-Container weiter, welcher sich wiederum im Private Subnet befindet. In der Web-App werden die Tierarztrechnungen und die Aufschlüsselungen (Informationsextraktionen) dargestellt.
Egress
Die Attribute der Tierarztrechnungen werden durch eine LLM-Integration extrahiert. Mittels LangGraph (Python-Lib) werden benutzerdefinierte Agenten orchestriert: einer für die Texterkennung (OCR), einer für die Kategorisierung der Rechnungsposten etc. Für die Extraktion wurde hauptsächlich ein OpenAI-Modell verwendet, welches wiederum durch Azure AI Foundry bereitgestellt wurde. Und hier ist der spannende Punkt: Dadurch, dass wir AI Foundry verwendet haben, musste die Anfrage die isolierte VPC verlassen. Hierzu wurde das im ersten Part erwähnte NAT Gateway verwendet, welches als Maske für den Multiagent-Container diente, da dieser im privaten Subnet keine öffentliche IP hatte. Dadurch konnte der Multiagent-Container sicher mit der Azure AI Foundry kommunizieren, ohne selbst für das Internet exponiert zu werden.
Nachdem die Daten erfolgreich extrahiert wurden, wurde das Ergebnis strukturiert im JSON-Format in S3-Buckets persistiert. Die Web-App stellte diese Ergebnisse wiederum für den User dar. Während der Multiagent prozessierte, wurden die Metriken und Outputs als Tracing-Daten an Langfuse gesendet – was den Observability-Teil bediente (Debugging, Monitoring, Outputs evaluieren, etc.). Das Langfuse-Dashboard wurde durch einen eigenen Server (Web-Interface) bereitgestellt.
Autorisierung statt Hardcoding
Wenn wir PoCs entwickeln, dann verstauen wir unsere Secrets und Environment Variables in .env-Files (und vergessen nicht, diese in .gitignore hinzuzufügen 😄). Wenn es darum geht, Container mit API-Keys und Secrets zu versorgen, ist es logisch, dass wir diese Informationen nicht in das Docker-Image schreiben. Stattdessen werden sie zur Laufzeit sicher in den Container injiziert. Hierzu ist der gängige Weg, den AWS Secrets Manager als Vault zu verwenden, um diese sensiblen Daten aufzubewahren. Gemäß dem Kredo Autorisierung statt Hardcoding, verwenden wir dynamische Referenzierungen (in dem Fall via Terraform), die auf Secrets verweisen, anstatt den Klartext-Key zu hinterlegen. Die Secret-Injiziierung in einen Container funktioniert in Azure Container Apps übrigens genau so: z.B. in Key Vault die Secrets anlegen und dann via secretref die Keys im Container referenzieren.
Der totale Durchblick
Und was hilft beim Troubleshooting während der Implementierung und des Betriebs? Der letzte Service, der das Bild vervollständigt: AWS Cloudwatch. Hier reicht auch ein Pfeil vom Fargate-Node zu Cloudwatch, denn alle Container (Multiagent, Langfuse, Web-App) senden ihre Logs an Cloudwatch. Dank des Zusammenspiels von analytischen Tracing-Daten in Langfuse und operativen Logs in Cloudwatch, können wir die Monitoring-Symbiose als vervollständigt ansehen. Natürlich kann Cloudwatch noch mehr als nur zentralisiert Logdateien von Anwendungen und Systemen anzeigen. Es bedient Metriken (Zeitreihendaten über die Performance von Ressourcen), Alarme (Definitionen von Schwellenwerten) sowie Events (Statusänderungen in AWS-Umgebungen) u.v.m. Für unsere Zwecke war der Debugging-Aspekt aber das Entscheidende. Hier wurde CPU-Auslastung, die geliebten Container-Crashes und 500er am ALB analysiert.
Fazit – Die Brücke zwischen PoC und Produktion
Damit sind wir am Ende. Wir haben uns durch den Komponenten-Dschungel gekämpft und dabei gesehen, dass eine fertige GenAI-App noch lange nicht das Ende der Fahnenstange ist. Für einen in der Cloud unerfahrenen AI Engineer würde ich deshalb empfehlen, beim Aufsetzen der Cloud-Umgebung, zumindest einen erfahrenen AI Architect, DevOps Engineer oder Cloud Engineer zu Rate zu ziehen. Diese Berufe haben nicht ohne Grund eine Daseinsberechtigung und erfüllen dedizierte Aufgaben im großen Kosmos der Softwareentwicklung. Noch einmal ein paar Aspekte, die ich bekräftigen möchte:
Zugunsten der Reproduzierbarkeit und der Stabilität
“Works on my machine” ist kein Deployment-Modell. Bitte an Terraform und Docker gewöhnen, Code versionieren, unkontrollierbares Konfigurationschaos dadurch vermeiden und das fragile Kartenhaus durch ein solides Fundament ersetzen.
Langfuse v3 und VPC-Setup
Das Bereitstellen des VPC-Setups sowie das Self-Hosting von Langfuse v3 war architektonisch anspruchsvoll und zeitfressend. Aber am Ende lohnt es sich doch. Durch die Isolation in Subnetze haben wir sensible Tierarzt-Daten gesichert und durch die Persistenz via EFS sichergestellt, dass die Traces nicht bei jedem Container-Neustart im digitalen Nirvana verschwinden. Ohne Deep-Tracing in Langfuse (oder einem anderen Observability-Tool — ist mir ja egal, was du verwendest, aber verwende IRGENDWAS! 😄) hast du einen Blindfleck, was die Agents für Zwischenausgaben machen (viel Spaß beim Evaluieren und Dagegensteuern) und kein Echtzeitmonitoring der Kosten, die sie verursachen. Transparenz ist hier der einzige Weg zur Optimierung und Profitabilität.
Abschlusswort: day 2
Es ist wichtig zu verstehen, dass der Betrieb einer GenAI-App ein Marathon ist. Neue Modelle der großen Anbieter können das eigene Resultat signifikant verbessern: besseres OCR, Verbesserungen im semantischen Verständnis, dadurch Anpassungen im Bereich Prompt Engineering notwendig, neues Function Calling etc. Gerade im Data Science- und AI Engineering-Bereich gibt es immer Raum zur Verbesserung, um Richtung Ground-Truth-Qualität zu konvergieren.
In Part 1 wurde schon angesprochen, dass die neueste GenAI-App-Version gar nicht automatisiert via CI/CD (Bitbucket-Pipeline, GitHub Actions, AWS CodeBuild, …) in ECR und ECS geupdatet wird. Die Images nicht mehr manuell pushen zu müssen ist natürlich ein Riesengewinn für die Effizienz und sollte immer im Scope miteinbezogen werden. Das Nutzerverhalten lässt sich durch unsere Logging- und Observability-Tools bestens monitoren. Sich damit zu beschäftigen, wann ECS-Tasks hochgefahren werden müssen, zahlt natürlich auf die Kostenoptimierung ein.
In dieser Blog-Reihe wurden die grundlegenden Komponenten zum Hosting der GenAI-App gezeigt, aber die GenAI-App arbeitet noch mit mehr AWS-Services: die Daten müssen gefetched, via Messaging Queue gesendet und partitioniert werden, Alerts für fehlgeschlagene Prozessierungen dürfen auch nicht fehlen… Diese Aspekte ergeben locker einen eigenen Beitrag, der noch weitere Blindflecke im Bereich AI Engineering aufdecken könnte. Ich hoffe ich konnte mit dieser AI Solutions Architecture-Reihe zumindest den ein oder anderen Blindfleck aufdecken.
Erfahre mehr zu unserem Service rund um Daten & KI:


