
In Part 1 zum Thema “Wie shippe ich erfolgreich eine production-ready GenAI-App”, haben wir beleuchtet, welche Sicherheitskomponenten eingebaut werden müssen, um einen Multiagent in AWS betreiben zu können.
In diesem Artikel wollen wir den Sicherheitskäfig (Network & Foundation) verlassen und uns um Compute, Containerisierung sowie um das Observability-Monster Langfuse kümmern. Nochmal kurz zur Erinnerung: Es wird detailliert die Architektur eines Realprojekts beschrieben. Ich möchte mit dieser Reihe Blindflecken aus dem Weg räumen, sodass ein AI Engineer zumindest in der Lage ist, die Aufwände nach dem PoC abschätzen und benennen zu können.
Hier ein kleiner Use Case-Abriss: Das Ziel beim Kunden war die Entwicklung einer GenAI-basierten App, die automatisch Daten aus Tierarzt-Rechnungen (PDFs) extrahiert und strukturiert. Die Extraktion erfolgte auf zwei Ebenen:
- Rechnungspositionen: Automatisches Auflisten, Kategorisieren (z. B. „Prävention“) und Erfassen von Einzelpreisen sowie Steuersätzen
- Metadaten: Auslesen allgemeiner Informationen wie Klinikdetails, Versichertendaten, Rechnungsdatum sowie spezifischer Tierinfos (Name, Rasse).
Infrastruktur
Wie bereits erwähnt, befassen wir uns heute damit, wie die Containerisierung sowie die Observability des Multiagents realisiert wurde. Zur Orientierung habe ich ein Architekturbild erstellt, welches die für diesen Artikel relevanten Komponenten visualisiert. Dieses Bild beinhaltet nicht Networking & Foundation sowie die LLM-Integration, um Komplexität rauszunehmen und das Ganze übersichtlicher zu halten. Im dritten und letzten Kapitel der Reihe bekommst du das Full Picture.
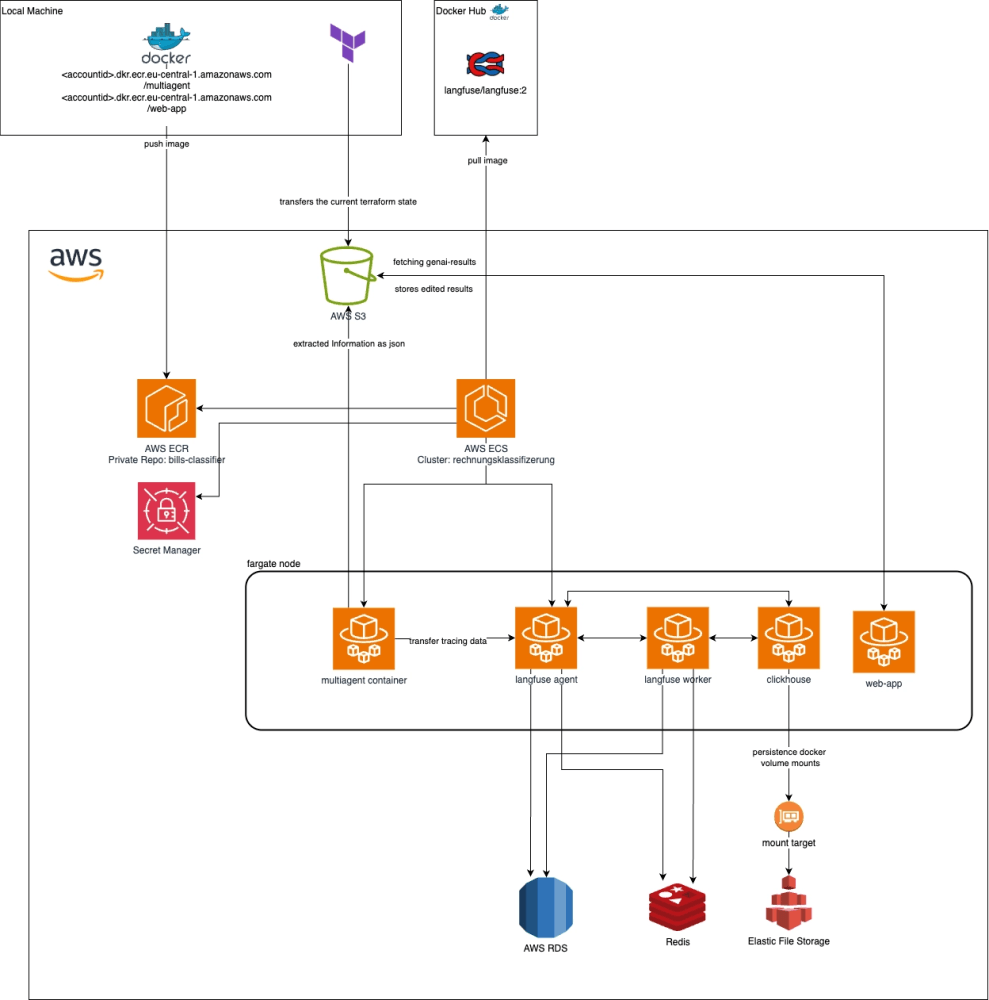
Der Weg in die Cloud
… ist gar nicht mal so schwer. Und das Schöne ist, dass das Azure-Pendant genau so funktioniert.
Terraform statt Klick-Odyssee
Zunächst mal muss der Code von der lokalen Entwicklungsumgebung in die Cloud gelangen. Die Cloud muss die Rechenleistung für die App außerdem so effizient wie möglich verwalten. Für den PoC ist es völlig legitim, erstmal mit der Cloud-UI die nötigen Komponenten und Services zusammenzuklicken. Mein Rat ist dennoch, schon so früh wie möglich von der Klickerei wegzukommen und die Infrastruktur in Terraform (oder einer IaC-Alternative) aufzusetzen. Man behält einen besseren Überblick darüber, was man überhaupt alles eingestellt hat (Cloud = Konfigurationschaos) und kann vor allem seine Umgebung jederzeit reproduzieren. Als Nicht-Cloud-Component-Engineer muss man sich daran erstmal gewöhnen – aber es lohnt sich. Der S3-Bucket ist hier als “Backend” für das State-File zu betrachten. Es speichert den aktuellen Zustand der Cloud-Infrastruktur. Ein zentraler State in S3 sorgt dafür, dass jeder Engineer mit dem gleichen Infra-Stand arbeitet.
Docker & AWS ECR
AWS ECR (Elastic Container Registry) ist die private Registry in der Cloud. Wir verpacken lokal mit Docker die Applikation und pushen das Image der neuesten Docker-App in die entsprechende Registry. Das haben die Entwickler in diesem Projekt manuell via CLI gemacht. Komfortabler wäre es natürlich, einen CI-Runner zu haben, der mithilfe einer Pipeline-Konfiguration das Ganze z. B. nach einem Merge auf den main-Branch automatisiert für uns erledigt. Das war in diesem Fall nicht im Projekt-Scope enthalten… anyway: der ECR fungiert als Storage für die fertigen Images. Durch den Container-Ansatz müssen unsere Ohren auch niemals den Satz “works on my machine” hören. Es wird sichergestellt, dass nur autorisierte ECS-Instanzen Zugriff auf den proprietären Code haben.
Die Laufzeitumgebung
AWS ECS & Fargate
In AWS definiert man logische Gruppierungen von Rechenressourcen, auf denen die Container-Apps letztlich ausgeführt werden: die AWS ECS (Elastic Container Service)-Cluster. Hier wird auch die Compute Engine Fargate konfiguriert, die ich im ersten Teil angesprochen habe. AWS ECS an sich ist ein Container-Orchestrierungsdienst und kümmert sich um die Bereitstellung, Verwaltung und Skalierung von Docker-Containern. Präziser ausgedrückt werden Task-Definitions gestartet und verwaltet. Das sind Blaupausen im JSON-Format, die beschreiben, wie ein Docker-Container ausgeführt werden soll. Während ECS steuert, welche Container wo laufen, kümmert sich Fargate um das Provisioning der Server. Wie im letzten Teil erwähnt, ist hier das Tolle, dass wir uns nicht um Patching, Skalierung oder Wartung kümmern müssen. Und man zahlt nur für die Rechenleistung, die die Container tatsächlich verbrauchen. Das reduziert den operationalen Overhead massiv.
Container
Wie in der oberen Abbildung zu erkennen ist, laufen fünf Container in derselben Laufzeitumgebung. Alleine drei existieren für das Observability-Tool Langfuse, auf das ich unten genauer eingehen werde. Da ich mich in dieser Reihe auf die Infrastruktur konzentriere, hier nur ein paar Worte zum Multiagenten-System: der Container multiagent container besitzt die KI-Logik. Durch LangGraph werden die verschiedenen Agents orchestriert und so die komplexe Dokumentenextraktion realisiert. Ein Agent kümmert sich um die Texterkennung, ein Agent um die Kategorisierung der Rechnungsposten etc. Außerdem sendet der Container Tracing-Daten an Langfuse. Im S3-Bucket landen die Resultate (JSONs) des Multiagents. Die Web-App greift sich die extrahierten Daten und stellt sie dann dem User in einer ansehnlichen UI zur Verfügung. Somit ist der GenAI-Workflow von der reinen Web-UI getrennt, was die Skalierbarkeit und Wartbarkeit während der Entwicklung vereinfachte.
Wichtig ist hier zu wissen, dass alle Container im selben ECS Task laufen. Da sie sich im selben Task befinden, teilen sie sich den Netzwerknamensraum (awsvpc) und können über localhost kommunizieren. Wir müssen uns deshalb nicht um umständliche Endpoints bemühen und können die Kommunikation zwischen den Containern schmerzfrei implementieren.
Observability-Monster: Langfuse v3
Apropos schmerzfrei. Schmerzfrei war das Self-Hosting von Langfuse nicht. Das wäre noch entspannt gewesen, wenn wir im Projekt Version 2 und nicht Version 3 deployt hätten. Aber unser Anspruch ist natürlich, die neueste stabile Version zu verwenden und bei Projektstart nicht schon direkt mit den Versionen hinterherzuhinken.
Langfuse ist ein mächtiges Tool für LLM-Tracing. Deswegen wollten wir es zum Monitoren und Debugging auch einsetzen. Es kann für Tracing, Evaluation und Prompt Management eingesetzt werden und spuckt äußerst nützliche Metriken wie Tokenverbrauch sowie separate Outputs der Agenten aus. Das alles war äußerst nützlich zur kontinuierlichen Verbesserung des Produkts. Warum die Bereitstellung des Tools etwas aufwändiger war, lässt sich anhand dieser Abbildung am besten beschreiben:
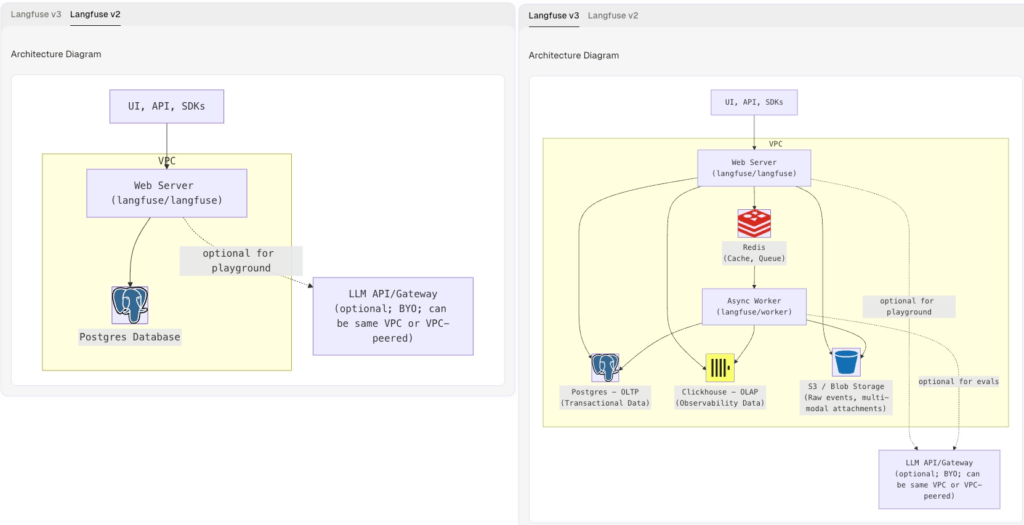
Langfuse hatte in 2024 sehr an Popularität dazu gewonnen. Das bisherige Postgres-basierte Setup von Version 2 (l.) hatte wohl nicht mehr ausgereicht, um die Skalierbarkeit zu gewährleisten, dass sich das Langfuse-Team erhofft hatte. Daher kamen folgende Komponenten hinzu, die so auch in der oberen Architekturabbildung wiederzufinden sind:
- AWS RDS: Verwaltete SQL-Datenbank (Postgres). Speichert Metadaten und User-Infos.
- Redis: Queuing von Events und Caching. Verhindert Systemüberlastung bei Burst-Traffic durch Zwischenpuffern (Asynchrone Verarbeitung).
- Clickhouse: OLAP-DBMS für Traces, Observations und Scores. Optimiert für extrem schnelle analytische Abfragen.
- Langfuse Agent & Worker: Der „Web“-Container (API) nimmt Daten entgegen, der Worker verarbeitet sie im Hintergrund (z. B. für die Token-Kostenberechnung).
Ich glaube der Punkt ist deutlich geworden, dass das Aufsetzen von Langfuse architektonisch wesentlich anspruchsvoller geworden ist, da es aus mehreren Komponenten besteht. Clickhouse als OLAP DBMS hat hier noch am meisten Probleme bereit, da dessen Default-Konfigurationen nicht direkt funktionierten und an Service Connect Konfigurationen Anpassungen vorgenommen werden mussten.
Clickhouse selbst ist durch Fargate gehostet. Und da Fargate-Container „ephemer“ (flüchtig) sind, benötigen wir einen Persistence-Layer, damit die wertvollen Tracing-Daten nicht verloren gehen. Hierzu wurde AWS EFS (Elastic File System) eingesetzt. Das ist ein netzwerkbasiertes File Storage und hilft bei der persistenten Speicherung. Durch den Mount Target, der im letzten Teil schon erwähnt wurde, wird das Dateisystem direkt in den Clickhouse-Container eingebunden.
Die Brücke zwischen PoC und Produktion
So schnelle und bemerkenswerte Ergebnisse man mit einem GenAI-Projekt auch erzielen mag, ich hoffe ich konnte in diesem Artikel verdeutlichen, dass der Sprung vom lokalen Prototypen zur produktionsreifen GenAI-Architektur weit mehr ist als ein “schnelles Hosting in der Cloud”. Durch Terraform, Docker, AWS ECS und Fargate erschlägt man wichtige Themen wie Reproduzierbarkeit, Ausfallsicherheit und Server-Management. Es gibt aber auch Themen, die einen erstmal aufhalten können: eine konsequente Abschottung zur Außenwelt, die Zeit die man in Langfuse v3 investiert und um dessen Komponenten zum Laufen zu bringen. In dieser Reihe lag mein Fokus nicht auf die Web-App, aber das Betreiben dieser birgt natürlich auch weitere Aufwänden, vor allem zur Realisierung von HTTPS. Da kommen schnell weitere Services wie Route 53, ALB, ACM, VPC und mehr hinzu. Zu Langfuse sei gesagt: wer es selbst hostet und die Zeit investiert, gewinnt absolute Transparenz über Agent-Workflows und Kosten sowie ein nützliches Tool für Debugging sowie Tracing. In jedem Fall ist ein Observability-Tool zur GenAI-Entwicklung zu empfehlen.
Im dritten und letzten Teil dieser Reihe führen wir alle Fäden zusammen: Wir werfen einen Blick auf das Full Picture und genießen die vollumfängliche Komplexität der Architektur. Stay tuned!


