Ylikorostunut teknologianäkökulma
Mediassa big dataa käsitellään yleensä hyvin teknologialähtöisesti. Hadoop ja vastaavat teknologiat ovat keskustelun ytimessä. Näitä teknologioita käytetään pääsääntöisesti yksittäisissä hankkeissa ja tietojärjestelmissä korvaamaan mm. perinteisiä relaatiotietokantoja ja hakemistoja rakenteettoman tiedon tallennuksessa ja käsittelyssä. Näiden teknologioiden käyttö onkin monesti perusteltua sekä tiedon tallennuksen kustannustehokkuuden että hajautettuun ja rinnakkaistettuun tiedon prosessointiin liittyvän ohjelmointikyvykkyyden lisäämisen näkökulmasta. Mikäli organisaatiossa halutaan hyödyntää tietopääomia yksittäisiä sovelluksia laajemmin ja hyödyntää big dataa esimerkiksi tiedolla johtamiseen, pitää big dataa pystyä yhdistämään joustavasti ja laaja-alaisesti muihin tietoihin. Tämän onnistuminen ei ole useinkaan kiinni teknologioista vaan laajemmin menetelmistä, arkkitehtuurista, mallinnus- ja toteutustavoista.
”ETL is dying” – perinteisen tietovarastoinnin skaalautuvuusongelmat
Big datan hyödyntämisestä tietovarastoinnissa on runsaasti erilaisia näkemyksiä. Isojen tietokantatoimittajien määrittelemä tapa perustuu usein Hadoopilla tai vastaavalla map-reduce pohjaisella prosessointiteknologialla toteutettuun datan kutistamiseen ja kutistetun tiedon viemiseen tietovaraston raportointirakenteisiin. Kutistaminen voi olla esimerkiksi tiedon suodattamista tai koostamista. Kyseessä on kuitenkin Data Vault kehittäjän Dan Linstedtin kuvaama antisuunnittelumalli (antipattern), jossa liiketoimintasäännöt yhdistetään tiedon lataamiseen ja integraatiologiikkaan. Ongelmana on skaalautumattomuus sekä uusien tietolähteiden että liiketoimintasääntöjen lisäämiseen osalta. Uuden tietolähteen lisäystä ei voi tehdä vain uutta ETL-latausprosessia (Extract-Transform-Load) kirjoittamalla, vaan olemassa olevia latausprosesseja pitää muuttaa, jotta niihin sisältyvät liiketoimintasäännöt kykenevät huomioimaan uuden tietolähteen tarjoaman tiedon. Yksittäinen ETL-prosessi monimutkaistuu merkittävästi tietolähteiden kasvaessa, monimutkaistaen prosessiin sisällytettävän liiketoimintasäännön muokkaamista tai uuden liiketoimintasäännön lisäämistä. Mitä suuremmaksi siis tietovarasto kasvaa sitä monimutkaisemmaksi ja työläämmäksi uuden tietolähteen tai liiketoimintasäännön lisäys käyvät. Jossain vaiheessa muutostyön määrä voi helposti kasvaa niin suureksi, ettei tietovarasto kestä enää uusia lisäyksiä.
Big datan käsittelyn näkökulmasta edellä kuvatut skaalautumisrajoitteet ovat kestämättömiä. Tarkoituksenahan on juuri kyetä hyödyntämään laajamittaisesti organisaation erimuotoisia tietolähteitä ja saada uusia asioita irti olemassa olevasta tiedosta. Dan Linstedtin mukaan edellä kuvatulla tavalla ei ole tulevaisuutta ja hän onkin todennut: ”ETL is dying”. Data Vault 2.0 arkkitehtuurissa tietojen tuominen tietovarastoon (raakadata vault) on erotettu omaan kerrokseensa liiketoimintasäännöt huomioivasta business vault-kerroksesta ja raportointirakenteiden määrittelystä (information mart area). ETL-prosessista on näin saatu T eli muunnokset pois. EL-prosessi ei tarkoita kuitenkaan tietojen suoraa kopiointia, vaan tuontiin voi liittyä ns. kovia sääntöjä (hard rules) kuten tietotyyppien muunnoksia tai tietojen normalisointia.
Erillisten kerrosten ansiosta liiketoimintasääntöjen muuttaminen ei vaikuta lainkaan tietojen latausprosesseihin. Tietolähteiden lisäämisellä on puolestaan vähäiset tai ei lainkaan vaikutuksia olemassa oleviin liiketoimintasääntöihin ja raportointirakenteisiin. Koska vanhoja latausprosesseja ja malleja ei tarvitse juurikaan päivittää, tietovaraston koolla ei ole vastaavaa vaikutusta työmääriin ja kustannuksiin kuin perinteisessä kaksitasoisessa tietovarastoinnissa. Koska latausprosessit eivät sisällä liiketoimintalogiikkaa, niiden määrä pysyy myös perinteistä mallia vähäisempänä ja niistä muodostuu varsin yksinkertaisia, nopeita ja suoraviivaisia tiedonsiirtoja, jotka ovat keskenään melko samanlaisia. Tämä puolestaan mahdollistaa latausprosessien kehittämisen ja hallinnan automatisoinnin.
Lisäksi Data Vault 2.0 ja perinteiselle arkkitehtuurilla on merkittävä ero tietovaraston suorituskyvyn skaalautuvuuteen. Liiketoimintasääntöjen puuttuminen ja tiedot toisistaan hyvin eriyttävä Data Vault 2.0 mallinnus mahdollistavat latausprosessin suorituksen rinnakkaistamisen, mikä ei ole perinteisessä mallissa samassa laajuudessa mahdollista. Perinteisessä mallissa rinnakkaista ja laiteresursseihin skaalautuvaa prosessointia rajoittavat merkittävästi liiketoimintasääntöjen ja raportointirakenteiden (esim. tähtimalli) edellyttämät tietojen yhdistämis- ja koostamisvaatimukset sekä muut riippuvuudet tuotavien tietojen välillä.
Monimuotoinen big data ei taivu yhteen muottiin
Big dataa käsitellään usein harhaanjohtavasti erillisenä saarekkeenaan, jota pitäisi käsitellä täysin uudenlaisesti ja uusilla teknologioilla. Tyypillisesti big data kuitenkin koostuu erityyppisistä, kokoisista ja muotoisista tietojoukoista, joiden perusteella käsittelytapa ja -teknologiat kannattaa valita.
Rakenteellinen tieto kannattaa usein siirtää relaatiotietokantamuotoiseen tietovarastoon, jotta sen jatkokäsittely olisi mahdollisimman yksinkertaista, kustannustehokasta, helposti automatisoitavissa ja tukisi mahdollisimman hyvin olemassa olevaa osaamista ja organisaation käyttämiä tiedon anlysointi- ja visualisointityökaluja. Tiedon koon tai tietovirran nopeuden ollessa todella suurta, kannattaa tieto prosessoida kustannustehokkailla rinnakkaista hajautettua prosessointia tukevilla alustoilla. Näihin lukeutuvat myös osa sql-kieltä tukevista tietokantaratkaisuista. Rakeenteellisen tiedon määrä ja tietovirran nopeus ovat nykyisin kuitenkin hyvin harvoin esteenä tietojen viemiselle relaatiotietokantapohjaiseen tietovarastoon, jos sen tietomalli ja arkkitehtuuri on suunniteltu tehokkaaseen tiedon tuontiin ja integrointiin. Tehokas tiedon tuonti on ollut Data Vault mallinnuksen ja arkkitehtuurin keskeisenä lähtökohtana. Jos tieto prosessoidaan matalan tason teknologioita käyttäen, kuten esim. suoraan Hadoop-tiedostojärjestelmän päällä, kannattaa tulokset siirtää tietokantaan, jossa niitä on käyttäjien helpompi analysoida, visualisoida, yhdistää muihin tietoihin ja jatkokäsitellä käyttäjille entuudestaan tutuilla BI-tuotteilla.
Rakenteeton tieto ja siihen liittyvät käsittelyvaatimukset eroavat usein merkittävästi rakenteellisesta tiedosta ja sen käsittelyvaatimuksista. Esim. kuvien ja videoiden koot voivat olla massiivisia eivätkä perinteiset relaatiotietokannat anna näiden sisällön käsittelyyn parhaita eväitä. Yhtenä vaihtoehtona on viedä tiedostojen metatiedot tietovarastoon ja varsinaisen sisällön tallennus ja mahdollinen analysointi hoitaa esim. Hadoop-pohjaisilla tiedontallennusalustoilla, jotka skaalautuvat kustannustehokkaasti suurillekin tietomäärille.
Data Vault 2.0:n arkkitehtuuri huomioi big datan monimuotoisuuden ja edellä kuvatut erilaiset käsittelytavat eikä malli yksinkertaista big datan käsittelyä virheellisesti yhteen muottiin. Alla olevassa kuvassa on esitetty DV 2.0:n mukaiset arkkitehtuuritasot ja big datan kytkeytymisvaihtoehdot eri tasoille.
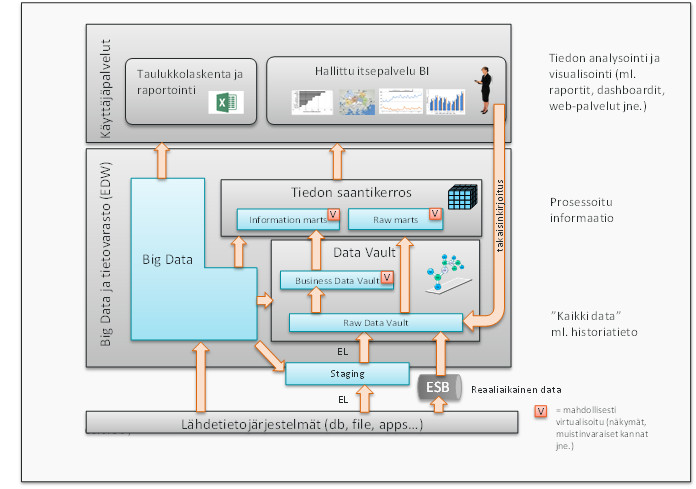
Perinteiseen kaksikerroksiseen tietovarastoinnin arkkitehtuuriin ja tietomallinnukseen liittyy edellä kuvattujen lisäksi runsaasti muitakin keskeisiä haasteita, jotka korostuvat entisestään big datan myötä. Näitä ovat mm. heikko tuki toimintalähtöiselle ketterälle kehittämiselle ja tietosuojavaatimusten huomioimiselle. Data Vault 2.0 järjestelmään pohjautuvia ratkaisumalleja näihin ongelmakohtiin on kuvattu tarkemmin blogeissa Data Vault 2.0 – tietovarastojen villin lännen ”pieni suuri” metodi? ja Tietosuojan ja henkilörekisterien käsittelyn sudenkuopat tietovarastoinnissa.


