Puheentunnistusteknologiaa hyödyntävät älykaiuttimet ja virtuaaliapurit ovat lyöneet jo isosti läpi maailmalla. Esimerkiksi Yhdysvalloissa viime vuonna älykaiuttimien käyttäjiä ennustettiin olevan jo yli 80 miljoonaa kappaletta (TechCrunch). Suomessa vastaavaa markkinaa ei ole vielä päässyt syntymään, koska suomen kielen tuki puuttuu monista älykaiuttimista ja puhelimien virtuaaliapureista. Viime vuosina Suomeenkin on kuitenkin syntynyt puheentunnistusteknologiaa kehittäviä yrityksiä ja sovelluksia, joilla voi vaikkapa luoda kaupan ostoslistan puheella (Tivi). Avoimen lähdekoodin suomenkielistä puheentunnistusteknologiaa ei tosin vielä ole kovin paljoa saatavilla.
Avoimen lähdekoodin uusimpia tekoälyyn perustuvia luonnollisen kielen käsittelyn (Natural Language Processing, NLP) ja uutena valtauksena myös puheentunnistuksen (Automatic Speech Recognition, ASR) teknologioita kehitetään Hugging Face -nimisessä startupissa ja sen ympärille muodostuneessa yhteisössä. Maaliskuun lopulla Hugging Face organisoi kampanjaviikon, jonka tavoitteena oli kehittää avoimia puheentunnistusmalleja erityisesti vähän puhutuille kielille, kuten suomelle. Olemme aiemmin hyödyntäneet Hugging Facen teknologioita suomenkielistenkin kielimallien kouluttamiseen, joten suomenkielisen puheentunnistusmallin kehittäminen kuulosti kiinnostavalta haasteelta. Kampanjaviikon päätteeksi parhaat mallit vieläpä luvattiin palkita Hugging Facen palkinnoilla, joten kiinnostuksemme oli taattu!
Puheentunnistuksen perusteet
Puhe kulkee ilmassa värähtelynä eli ilmanpaineen muutoksina eli ääniaaltoina. Digitaalisessa muodossa ääniaalto voidaan esittää numerosarjana, joka kuvastaa suhteellista ilmanpainetta tietyllä ajanhetkellä. Ääniaalto on luonteeltaan jatkuva signaali, joten digitaalisessa formaatissa se yleensä jaetaan tietynkokoisiin diskreetteihin näytteisiin (sampling). Näytetaajuudella (sampling rate) kuvataan, kuinka monta näytettä sisältyy yhteen sekuntiin. Ääniaallolla on tietty taajuus, jonka sisällyttämiseksi näytteeseen tarvitaan kaksinkertainen näytetaajuus ääniaallon taajuuteen verrattuna. Ihminen kuulee korkeimmillaan 20 kHz taajuuksia, joten digitaalisen äänen yleisesti käytetty näytetaajuus on 44.1–48 kHz eli hieman yli kaksinkertainen verrattuna ihmisen kuulon ylärajaan. Nämä äänifysiikan perusteet on hyvä tiedostaa myöhemmässä luvussa, jossa kerrotaan puheentunnistusmallin kehittämiseen käytettävän digitaalisen äänidatan käsittelystä muun muassa näytetaajuuden muuntamisen osalta.
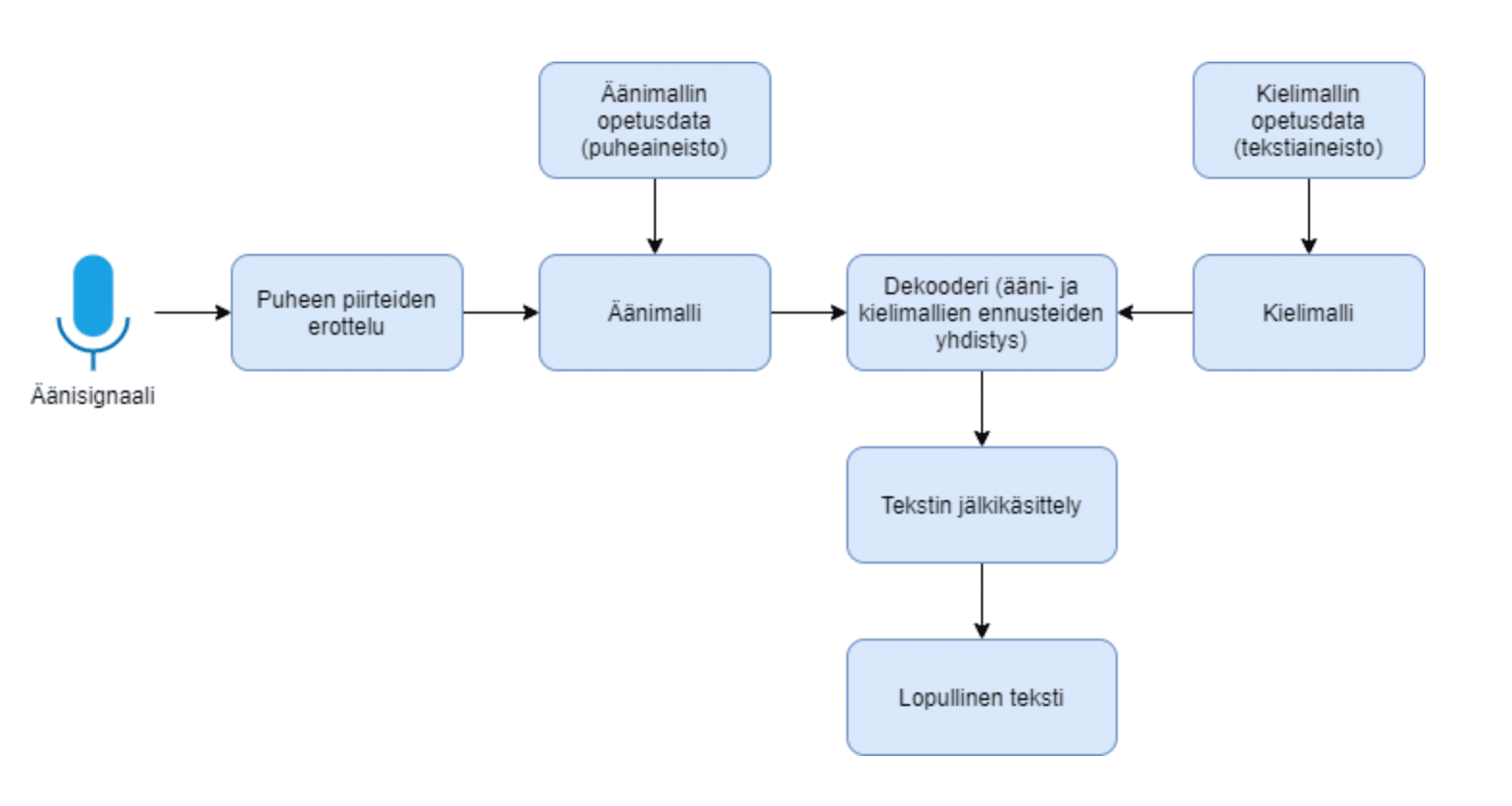
Puheentunnistukseen, eli puheen automaattisesta muuntamisesta tekstiksi, sisältyy yleensä muutamia välivaiheita, joita on visualisoitu alla olevassa kuvassa. Usein ensimmäiseksi puhetta sisältävä digitaalinen äänisignaali pilkotaan pieniin osiin, jotta niistä voidaan helpommin erottaa puheen eri piirteitä. Piirre voi vastata esimerkiksi yhden kirjaimen äännettä tai äänteen osa. Seuraavaksi piirteet syötetään äänimallille, joka pyrkii ennustamaan, mitä merkkiä kyseinen piirre vastaa. Merkki voi olla esimerkiksi kirjain tai välilyönti. Äänimalli voidaan toteuttaa erilaisin tavoin tilastollisista menetelmistä syviin neuroverkkoihin. Kun äänimalli ennustaa useita peräkkäisiä merkkejä, merkeistä alkaa muodostua tekstiä. Äänimalli itsessään ei sisällä tietoa puhutun kielen sanoista tai kieliopista, joten tätä puutetta voidaan paikata erillisellä kielimallilla. Kielimalli on opetettu laajalla tekstiaineistolla, josta se on oppinut esimerkiksi, mitkä sanat seuraavat tyypillisesti toisiaan eri yhteyksissä. Dekooderi yhdistääkin äänimallin ja kielimallin niin, että äänimallin tuottamia merkkiennusteita voidaan ohjata kielellisesti oikeaan suuntaan kielimallin tuottamien ennusteiden avulla. Näin tuotettu teksti sisältää vähemmän kirjoitusvirheitä. Lopulta tuotettua tekstiä voidaan vielä jälkikäsitellä, jotta esimerkiksi lauseiden välimerkit ovat kohdillaan.
Esiopetetut äänimallit
BERT, GPT-3 ja muut viime aikoina kiinnostusta herättäneet kielimallit ovat kasvaneen laskentatehon, suurten datamassojen sekä kehittyneiden koneoppimisalgoritmien ansiosta. Yksi keskeinen innovaatio suuren datamäärän hyödyntämiseen on itseohjattu oppiminen (self-supervised learning), jossa luokittelematonta aineistoa itsessään käytetään mallin opettamiseen. Esimerkiksi kielimalli voidaan opettaa hakemalla suuri määrä tekstiä internetistä, piilottamalla vuorollaan tekstin jokainen sana ja antamalla mallin ennustaa piilotetut sanat ympäröivän tekstin perusteella. Tällaista itseohjattua opetusta käytetään mallin esiopettamiseen, jonka jälkeen sitä voidaan edelleen opettaa luokitellulla datalla. Tällöin dataa tarvitaan huomattavasti vähemmän, koska malli osaa jo muodostaa järkeviä assosiaatioita kieliopin, sanaston, sekä semanttisten piirteiden välillä.
Tyypillisesti äänimallit opetetaan alusta asti luokitellulla datalla ilman yllä kuvattua esiopetusvaihetta. Tämä vaatii paljon laskentatehoa, aikaa, sekä valmiiksi litteroituja äänityksiä. Valmiiksi litteroitua ja helposti saatavilla olevaa data-aineistoa löytyy suomeksi melko niukasti ja raa’an äänidatan litterointi on taas aikaa vievää työtä. Facebookin viime vuonna julkaisema Wav2Vec2-malli kuitenkin osoittaa, että tekstimallien kehityksessä jo vakiintunut itseohjattu oppiminen soveltuu myös äänimallien kehittämiseen. Tämän lähestymistavan kiistaton hyöty on se, että esiopetukseen voidaan käyttää litteroimatonta äänidataa. Kun mallille on jo valmiiksi opetettu, millaiset puheen piirteet tyypillisesti esiintyvät yhdessä, vaatii mallin jatko-opetus huomattavasti vähemmän litteroitua dataa kuin tavanomaiset äänimallit.
Wav2Vec2-malli hyödyntää itseopetusta ennustamalla niin sanottuja puheyksiköitä 25ms pituisiksi pilkotuista äänisignaalin osista, jotka ovat muodostettu raa’asta äänisignaalin datasta käyttäen konvoluutioneuroverkkoa. Neuroverkkojen perusteista voit myös lukea tarkemmin tästä blogista. Puheyksiköiden tarkoitus on oppia puheen piirteitä, jotka ovat vielä hienojakoisempia kuin puheen pienimmät merkitykselliset ääniyksiköt. Puheyksiköiden lukumäärä on rajattu siten, että malli pyrkii oppimaan puheyksiöihin eniten informaatioarvoa tuottavaa puheen piirteitä eikä esimerkiksi erilaisten puhujien puhetyylejä tai äänitteen taustamelua. Itseohjattu opetus Wav2Vec2-mallissa tapahtuu piilottamalla osa näistä puheyksiköistä mallin komponentilta, joka pyrkii päättelemään piilotetun puheyksikön ympäröivien äänipiirteiden perusteella.
Facebookin julkaisun mukaan edellä kuvattu menetelmä tuottaa englannin kielellä ennätyksiä rikkovia tuloksia. Tästä mallista on opetettu myös monikielinen versio nimeltään Wav2Vec2-XLSR-53 käyttäen 53 eri kieltä. Monikielinen versio mallista oppiikin puheyksiköitä, jotka voivat olla jaettuja eri kielten välillä. Tämä mahdollistaa sen, että vähäresurssiset kielet, kuten suomen kieli, voivat hyödyntää samankaltaisista kielistä opittuja puheyksiköitä. Monikielisen mallin esiopetuksessa ei valitettavasti ollut mukana suomenkieltä, mutta mukaan oli päässyt vironkielistä puhedataa. Voisikin kuvitella, että monikielinen malli sisältäen suomea muistuttavan kielen puheyksiköitä edesauttaisi myös suomenkielisen äänimallin jatko-opetusta. Ainakin tekstipohjaisten monikielisten kielimallien puolella on jo saatu aikaan tosi lupaavia tuloksia, joista voit myös lukea lisää tästä aiemmasta blogista.
Suomenkielisen puhedatan metsästys ja käsittely
Tyypillisesti isot mallit tarvitsevat paljon dataa. Hieman yksinkertaistaen voidaan sanoa, että mallin parametrien määrä kuvaa mallin kykyä oppia piirteitä datasta. Vaikka Hugging Facen kampanjassa tarkoituksena olikin hyödyntää Facebookin julkaisemaa isolla datamäärällä jo esiopetettua monikielistä äänimallia, riittävän datamäärän haaliminen on ehtona kohtuullisen mallin jatko-opettamiselle. Tarpeeksi suuren ja laadukkaan litteroidun suomenkielisen puhedatan löytäminen tulisikin todennäköisesti olemaan pullonkaula mallin jatko-opetuksessa.
Hugging Facen kampanjassa suositeltiin käytettävän Mozillan Common Voice -puhedataa, koska se sisältää kohtuullisen määrän litteroitua dataa monelle eri kielelle. Common Voice data on myös helposti ladattavissa eikä sen lisensointi ei aseta käytölle rajoituksia. Ikävä kyllä, Common Voice sisälsi suomenkielistä puhetta litteroituna vain noin yhden tunnin verran, mikä on huomattavasti vähemmän kuin joillekin verrokeille (ruotsi 12h, viro 19h, englanti 1686h). Emme tyytyneet yhteen tuntiin puhetta, vaan hetken googlailun jälkeen saimme lisättyä suomenkielisen puhedatan määrää vanhoista äänikirjoista sekä eduskunnan täysistunnoista. Lopullinen opetusdatamme sisälsi noin 12 tuntia suomenkielistä puhetta.
Mallin opetusta varten dataa tulee hieman esikäsitellä. Puhedatasta voi olla hankalaa erottaa lauseiden välimerkkejä ja isoja kirjaimia esimerkiksi erisnimien yhteyksissä, mitä ei eksplisiittisesti sanota ääneen normaalissa puheessa. Täten puheiden litteroinneista poistettiin kaikki väli- ja erikoismerkit sekä teksti muutettiin sisältämään vain pieniä kirjaimia. Litterointitekstien numerot olisi myös hyvä muuntaa puhuttuun muotoon.
Kasaan haalittu datajoukkomme asettaa myös tiettyjä haasteita. Ensimmäiseksi, Hugging Facen kampanjassa mallin testaus tehdään Common Voicen testidatalla, joten mallin tulee toimia ensisijaisesti vastaavissa ääniolosuhteissa. Näihin kuuluu akustinen ympäristö, äänitykseen käytetty mikrofoni sekä puhujat. Esimerkiksi suomenkielinen Common Voice on sukupuolijakaumaltaan selvästi vinoutunut sisältäen lähinnä miesten puhetta, joten hyvin testidatalla pärjäävä malli ei välttämättä sovellu todelliseen käyttöön. Tämä tulee ottaa huomioon myös muuta dataa käytettäessä. Esimerkiksi äänikirjoista saimme määrällisesti paljon dataa, mutta kaikilla kirjoilla on sama lukija, puhe on tyypillisesti rauhallisempaa ja sisältää vähemmän taustakohinaa kuin testauksessa käytetty data. Vastaavasti myös eduskunnan täysistunnoista äänitetyssä datassa on omat erityispiirteensä.
Edellä mainituista datan haasteista johtuen kokeilimme teknisesti monimuotoistaa puhedataa, jotta malli voisi paremmin oppia erilaisia ääniolosuhteita ja olla yleiskäyttöisempi. Lisäsimme satunnaisesti dataan esimerkiksi taustakohinaa ja muutimme puheen nopeutta sekä sävelkorkeutta. Puhedatan monimuotoistamisessa hyödynsimme valmista Python-kirjastoa nimeltään audiomentations. Ideaalitilanteessa käytettävissämme olisi ollut paljon hyvin erilaista ja monimuotoista puhedataa, mutta tällä kertaa tyytyminen oli datan teknisiin käsittelyn menetelmiin.
Eri lähteistä kerätyt mahdollisesti erilaisilla näytetaajuuksilla varustetut äänisignaalit tulee vielä muuntaa samaan näytetaajuuteen. Koska Facebookin Wav2Vec2-XLSR-53 malli oli esiopetettu puhedatalla, jonka näytetaajuus oli 16 kHz, myös mallin jatko-opettamiseen käytettävä puhedata tulee muuntaa samaan 16 kHz taajuuteen. Ihmisen puhesignaalin suurin informaatioarvo usein miten sijaitsee alle 8 kHz taajuuksissa, joten näytetaajuuden muunnos esimerkiksi yleisesti käytössä olevasta 44.1–48 kHz taajuudesta pienempään 16 kHz taajuuteen ei siis vielä vaaranna puheentunnistusmallin opettamisen lopputuloksen laadukkuutta. Tämä muunnos onnistuu helposti Python-kirjastoilla kuten Librosa.
Suomenkielisen äänimallin jatko-opettaminen
Kun äänimallia aletaan opettamaan hyödyntämällä valmista esiopetettua mallia, tässä tapauksessa Facebookin monikielistä Wav2Vec2-XLSR-53 mallia, aluksi mallin parametrit alustetaan esiopetetun mallin parametreista. Esiopetetut parametrit sisältävät mallin ymmärryksen eri kielten puheyksiköistä sekä niiden välisistä riippuvuuksista, joka on opittu ennustamalla piilotettuja puheyksiköitä. Jatko-opetuksen aikana käytämme litteroitua suomenkielistä puhedataa ja opetamme mallia ennustamaan puhtaaksikirjoitettua tekstiä ääninäytteen perusteella. Tämän opetusprosessin aikana myös mallin puheyksiköt mukautuvat siten, että ne soveltuvat paremmin suomen kielelle.
Esiopetetun mallin parametrit sisältävät paljon hyödyllistä tietoa, jota haluamme käyttää myöhemmässä jatko-opetusvaiheessa. Tämä rajoittaa mahdollisuuksiamme tehdä muutoksia mallin arkkitehtuuriin tai sen käyttämiin komponentteihin. Jatko-opetusvaiheessa opetuksen lopputulokseen vaikuttamisen vaihtoehtoina ovatkin siis yleensä datan määrän kasvattaminen, edellisessä luvussa kuvattu datan esikäsittely sekä seuraavaksi esiteltävä mallin hyperparametrien säätäminen.
Mallin parametrit mukautuvat automaattisesti mallin opetuksen aikaisen optimoinnin avulla. Hyperparametrit puolestaan asetetaan manuaalisesti ja ne vaikuttavat mallin toimintaan sekä opetukseen – ja siten myös parametrien oppimiseen. Kokeilemalla eri hyperparametrien kombinaatioita huomasimme tämän itsekin.
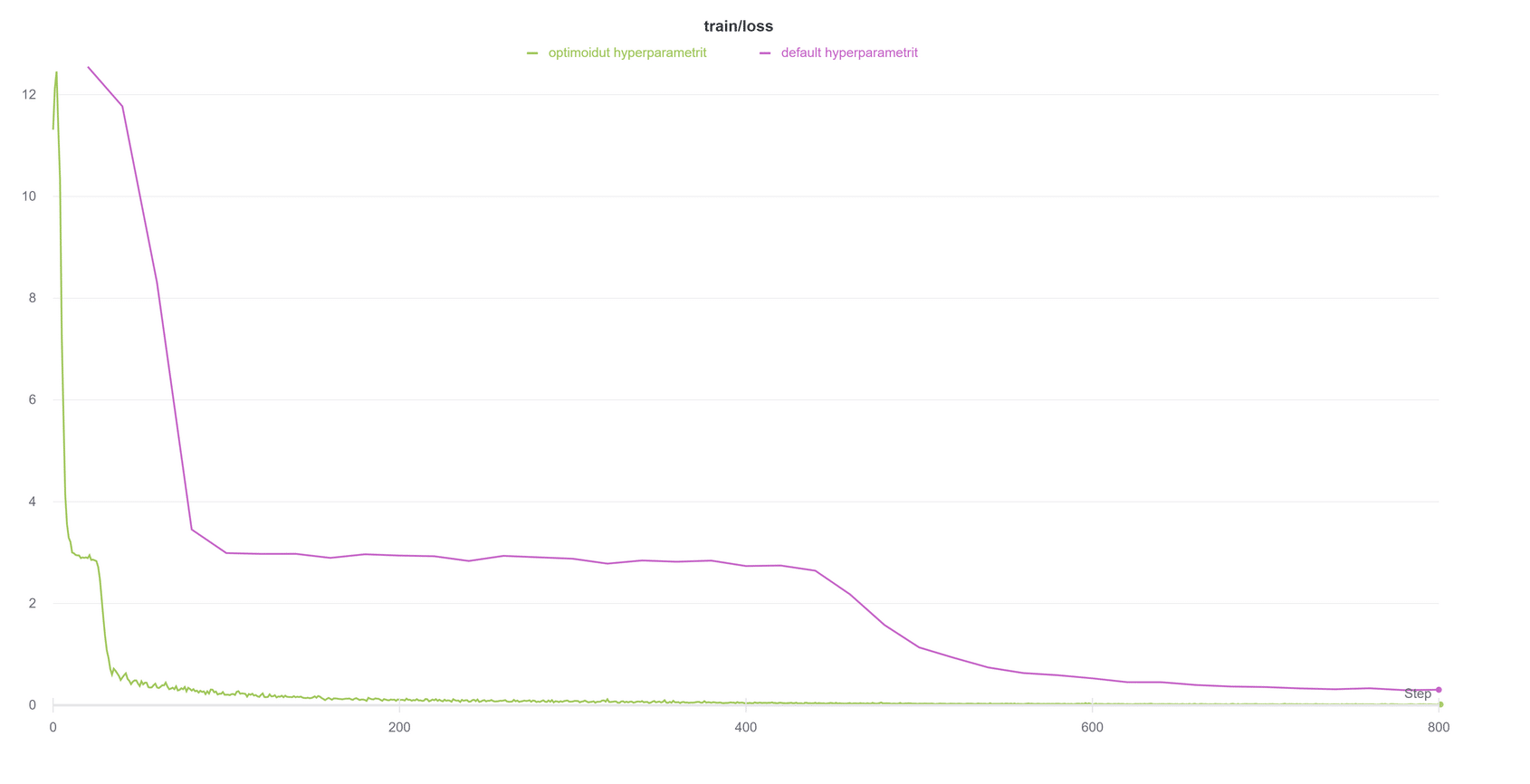
Lähdimme ensiksi kokeilemaan oletusarvoisia hyperparametreja. Näillä hyperparametreilla huomasimme, että usein mallin opetuksen aikainen virhe pieneni aluksi hyvin nopeasti, mutta sen jälkeen virheen muutos tasaantui ennen kuin jatkoi taas pienenemistään. Tämä voidaan huomata alla olevan kuvan violetista käyrästä. Tämä herätti epäilyksen, että mallin parametrien optimointialgoritmi olisi jäänyt niin sanotusti jumiin lokaaliin minimiin. Kokeilemalla eri hyperparametrien kombinaatioita löysimme arvot, joilla pääsimme tästä ilmiöstä eroon lähes kokonaan, kuten vihreä käyrä osoittaa. Nämä hyperparametrien muutokset paransivat mallin tarkkuutta sekä lyhensivät aikaa joka kului mallin opettamiseen.
Syviin neuroverkkoihin perustuvat mallit, kuten tässä käytetty äänimalli, tarvitsevat opetukseen myös paljon laskentatehoa. Opetimme malleja hyödyntäen ilmaista Googlen Colab -palvelua sekä Hugging Facen kampanjan puolesta tarjottuja resursseja. Valituista hyperparametreista ja opetusdatan määrästä riippuen mallien opetus kesti yleensä puolesta tunnista jopa 12 tuntiin, joten kahvia ja kärsivällisyyttäkin välillä tarvittiin!
Mallin opettamiseen käyttämämme koodi on vapaasti saatavilla Googlen Colabista, joten voit kokeilla itsekin oman mallisi opettamista.
Tulokset
Hugging Facen kampanjassa eri tahojen opettamia puheentunnistusmalleja eri kielille testattiin ja vertailtiin Mozillan Common Voice puhedata-aineiston kyseisen kielen testiosiolla, jota ei käytetty mallien opettamiseen. Testidatalla mallille laskettiin WER-lukema (Word Error Rate), joka kertoo mallin tuottaman tekstin virheellisten, puuttuvien ja ylimääräisten sanojen osuuden. Tavoitteena on siis saada mahdollisimman pieni WER-lukema.
Kampanjaviikon aikana opetimme lukuisia eri malleja suomen kielelle kokeillen erilaisia hyperparametrikombinaatiota sekä hieman erilaisia opetusdata-aineistoja. Ensimmäisten kokeiluiden WER-lukema oli noin 60 % tasolla, mutta lopulta saavutimme 32 % WER tason. WER-lukema siis melkein puolittui viikon aikana, joten itse puheentunnistusmallin oppimisen lisäksi myös mallin kehittäjätkin selvästi oppivat jotain. Viikon aikana suomenkielisiä malleja opetti meidän lisäksi muutama muukin, mutta lopulta meidän 32 % WER taso oli kaikista paras ja leikkimielisen kilpailun voitto ansaittu!
32 % WER tarkoittaa, että keskimäärin noin kolmannes mallin tuottamista sanoista on virheellisiä Common Voicen testidatalla. Kehittämämme malli ei siis todennäköisesti ole vielä tarpeeksi hyvä oikeaan tuotantokäyttöön, jossa WER tulisi olla mieluusti reilusti alle 10 %. Tosin WER-lukema ei välttämättä kerro koko totuutta mallin laadusta, koska virheelliseksi sanaksi lasketaan yhdenkin kirjaimen virhe. On myös hyvä huomioida, että kehitimme vain äänimallia. Huomattavasti parempaan WER lukemaan voitaisiinkin päästä opettamalla vielä erillinen kielimalli, yhdistämällä se äänimalliin dekooderilla ja lisäämällä loppuun tekstin jälkikäsittely.
Kehittämämme äänimallin tuotoksista on esitelty alla muutamia hyvin ja hieman huonommin onnistuneita esimerkkejä käyttäen Common Voicen testidataa. Kuten aiemmin mainittiin, malli ei yritä ennustaa puheesta lauseiden välimerkkejä tai isoja kirjaimia. Ne siis luonnollisesti puuttuvat mallin tuottamista teksteistä.

Itsekin puhetta äänittämällä ja testailemalla voi myös huomata, että välillä malli toimii paremmin ja joskus huonommin:

Voit myös käydä kokeilemassa mallin toimintaa Hugging Facen sivulta, jossa voit äänittää suoraan selaimesta tai lisätä äänitiedoston!
Yhteenveto ja suomenkielisen puheentunnistuksen tulevaisuus
Hugging Facen puheentunnistusmallien kehityskampanjaan osallistuminen oli mahtava kokemus ja pikakurssi puheentunnistuksen maailmaan. Kampanja oli myös hieno osoitus siitä mihin globaali avoimen lähdekoodin ympärille rakennettu yhteisö pystyy. Tähän kampanjaan osallistui yhteensä 380 henkilöä, jotka kehittivät yhdessä viikossa 179 puheentunnistusmallia 73 eri kielelle. Kaikki kehitetyt mallit ovat vapaasti saatavilla Hugging Facen mallikirjastossa, josta löytyy myös kehittämämme suomenkielinen puheentunnistusmalli. Voit siis ladata sen käyttöösi tai jatkokehitettäväksi tästä linkistä! Viime vuosien tekstipohjaisten luonnollisen kielen käsittelyn (NLP) mallien huima kehitys on tapahtunut hyvin pitkälti avoimen lähdekoodin periaattein ja muun muassa Hugging Facen yhteisön voimin. Vastaava kehitys voisi hyvinkin tapahtua tulevina vuosina myös puheentunnistusmallien parissa!
Suomenkielisen puheentunnistusmallin kehittämisestä opimme, että avoimesti saatavilla olevan suomenkielisen puhedatan määrä on vielä hyvin vähäistä ja data on melko yksipuolista sisältäen enimmäkseen miesten puhetta. Selvä tarve on siis monimuotoiselle litteroidulle suomenkieliselle puhedatalle, joka on avoimesti saatavilla vastaavien mallien kehittämistä varten. Toivomme, että Ylen ja Helsingin yliopiston organisoima Lahjoita puhetta -hanke paikkaa piakkoin tätä tarvetta. Käy sinäkin lahjoittamassa puhetta, jos et ole vielä sitä tehnyt!
Suomenkielistä puhedataa siis näyttäisi olevan tulossa lähiaikoina entistäkin enemmän, joten uusien mallien jatkokehitysmahdollisuuksia on luvassa. Suomenkielisten puheentunnistusmallien ja teknologioiden lähitulevaisuus vaikuttaakin valoisalta ja on hienoa olla mukana rakentamisessa sitä! Ehkä tulevina vuosina suomalaisissa kodeissakin yleistyvät älykaiuttimet ja virtuaaliapurit, jotka ymmärtävät suomenkielistä puhetta kaikilla murteilla nykyistä paremmin.
Missä sinä haluaisit käyttää suomenkielistä puheentunnistusta?