What kind of data companies have the most? Most likely text data like Word and PDF documents. For example, there could be documents about customer feedback, employee surveys, tenders, request for quotations and intranet instructions. International companies have those documents even in multiple different languages. How can you analyze multilingual documents with Natural Language Processing (NLP) techniques?
NLP is a subset of Artificial Intelligence (AI) where the goal is to understand human’s natural language and enable the interaction between humans and computers. The interaction can be both with spoken (voice) or written (text) language. Nowadays, many latest state of the art NLP techniques utilize machine learning and deep neural networks.
One of the NLP tasks is text classification. The goal of text classification is to correctly classify text into one or more predefined classes. For example, customer feedback text document could be classified to be positive, neutral or negative feedback (sentiment analysis). Request for quotation document could be classified to the backlog of the correct sales team of the company. Thus, the NLP model gets text as an input and outputs some class.
During the last couple years, NLP models based on the neural network “Transformer” architecture, like Google’s BERT model, have broken many records of different NLP tasks. Those models are really interesting and have even made headlines like too dangerous to be openly released. However, they mostly have only supported English or other popular languages. What if you would like to classify text in Finnish or Swedish or both?
Multilingual text classification
Until recently, openly released multilingual NLP models like Google’s multilingual version of the BERT have not performed as well as monolingual models especially in low-resource languages like Finnish. For example, monolingual Finnish FinBERT model clearly outperforms multilingual BERT in Finnish text classification task.
However, at the end of 2019 Facebook’s AI researchers published a multilingual model called XLM-R supporting 100 languages including Finnish. XLM-R was able to achieve state of the art results in multilingual NLP tasks and also be very competitive against monolingual models in low-resource languages. This new model looked very interesting so I decided to try it out for multilingual text classification.
Hugging Face’s “Transformers” Python library is really awesome for getting an easy access to the latest state of the art NLP models and using them for different NLP tasks. XLM-R model is also available with the Transformers library. We can take the pre-trained XLM-R model and utilize “transfer learning” concept to finetune the model to for example classify news article texts to news category classes. In the context of these NLP models, transfer learning means having a pre-trained general-purpose NLP language model which has been trained on a large text corpus (XLM-R was trained with more than two terabytes of text data!) and then the model is further trained with a lot smaller dataset to perform some specific NLP task like text classification.
For this experiment, my goal is to finetune the XLM-R model to classify multilingual news article texts to corresponding news categories. That is a supervised machine learning task so the dataset I am using is a labeled dataset containing news article texts and their category names. Another really interesting feature of the XLM-R and other multilingual models is their “zero shot” capability meaning you can finetune the model with a dataset of only one language and the model will transfer the learned knowledge to other supported languages as well. Since I am especially interested in Finnish language capabilities of the XLM-R model, the dataset contains only Finnish news articles with their categories. Thanks to the “zero shot” capability, the XLM-R model should also be able to classify news articles in other languages too in addition to Finnish. You can see an example of the dataset in the table below.
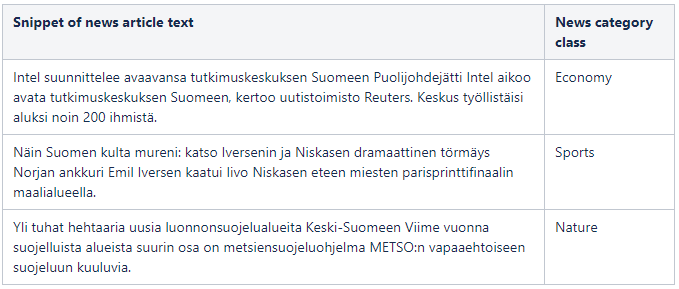
In total, there are only 3278 rows in my dataset so it is rather small but the power of earlier introduced “transfer learning” concept should mitigate the issue of small number of training data. The dataset contains 10 unique news category classes which are first changed from text to numerical representation for the classifier training. The dataset is also splitted into train and test sets with equal distribution of different classes. Finally, the XLM-R model is trained to classify news articles.
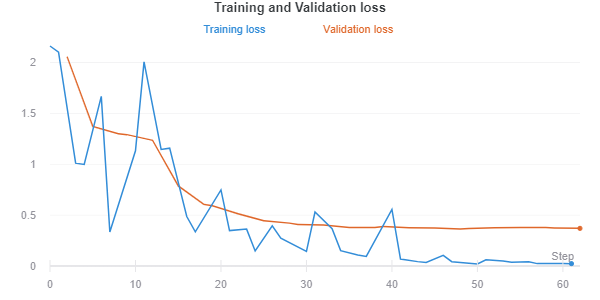
In the picture below you can see training and validation losses which both follow quite nice downward trend on training steps which means the model is learning to do classification more accurately. Validation loss is not increasing in the end so the finetuned XLM-R model should not be overfitted. Overfitting means that the model would learn too exactly classify text in the training dataset but then it would not be able to classify new unseen text so well.
Another model evaluation metric for multiclass classification is the Matthews correlation coefficient (MCC) which is generally regarded as a balanced metric for classification evaluation. MCC values are between -1 and +1 where -1 is totally wrong classification, 0 is random and +1 is perfect classification. With the testing dataset, the MCC value for the finetuned XLM-R model was 0.88 which is quite good. The result could be even better with larger training dataset but for this experiment the achieved performance is sufficient.
The most interesting part of the finetuned XLM-R model is to finally use it for classifying new news articles what the model has not seen during the earlier training. In the table below, you can see examples of correctly classified news articles. I tested the classification with Finnish, English, Swedish, Russian and Chinese news articles. The XLM-R model seemed to work really well with all of those languages even though the model was only finetuned with Finnish news articles. That is a demonstration of the earlier mentioned “zero shot” capability of the XLM-R model. Thus, the finetuned XLM-R model was able to generalize well to the multilingual news article classification task!

Multilingual vs monolingual NLP models
In the original research paper of the XLM-R model, researchers state that for the first time, it is possible to have a multilingual NLP model without sacrifice in per language performance since the XLM-R is really competitive compared to monolingual models. To validate that, I also decided to test the XLM-R against monolingual Finnish FinBERT model. I finetuned the FinBERT model with the exact same Finnish news dataset and settings than the earlier finetuned XLM-R model.
Evaluating performances of the FinBERT and XLM-R with the testing dataset showed that the monolingual FinBERT was only a little better in classifying Finnish news articles. In the table below, you can see evaluation metrics Matthews correlation coefficient and validation loss for both models.

This validates findings of Facebook AI’s researchers that the XLM-R model can really compete with monolingual models while being a multilingual model. While the FinBERT model can understand Finnish text really well, the XLM-R model can also understand 99 other languages at the same time which is really cool!
Conclusion
Experimenting with the multilingual XLM-R model was really eye-opening for me. Especially, the “zero shot” capability of the XLM-R model was quite jaw dropping at the first time when you saw the model classify Chinese news text correctly even though the model was finetuned only with Finnish news text. I am excited to see future developments in the multilingual NLP area and implement these techniques into production use.
Multilingual NLP models like the XLM-R could be utilized in many scenarios transforming the previous ways of using NLP. Previously, in multilingual NLP pipelines there have usually been either a translator service translating all text into English for English NLP model or own NLP models for every needed language. All that complicates the pipeline and development but with multilingual NLP models everything could potentially be replaced with a single multilingual NLP model supporting all the languages. Another advantage is the “zero shot” capability so you would only need a labeled dataset for one language which reduces the needed work for creating datasets for all languages in the NLP model training phase. For example, for classifying international multilingual customer feedback you could only create the labeled dataset from gathered one language feedback data and then it would work for all other languages as well.
This is mind-blowing and groundbreaking. One NLP model to rule them all?
Aapo Tanskanen