
The promise of Big Data has finally gained momentum. There is more data available than ever. While the amount of data increases, new innovations and technologies to utilise the data are constantly created. Big Data describes increasing amounts of data, which is constantly collected. Big Data can be filtered and turned into Smart Data. Smart Data can be described as cleansed, filtered, and prepared for the context form of Big Data. Work is about batches and off-line processing, where you capture-store-process data in overnight batch jobs. Fast Data reduces the time between capture and process. Fast Data aims for real-time data processing, where data is processed as soon as it arrives.
Data technologies are evolving. Both the way data is processed and the timeline when data is analyzed are changing. Data is collected from countless systems and analyzed in real-time. Data includes transaction data and business data, IoT metrics, operational information, and application logs.
The Fast Data revolution has been made possible by two underlying revolutions of Big Data and Smart Data. Big Data systems like Hadoop made it possible to store huge constant volumes of unstructured data on commodity hardware. For example, the Cassandra storage technology began from the need of Facebook to store high volumes of data. Currently, on Facebook, 2000 photos per second are uploaded. However, the challenge that Facebook faced, starts to be an every-day challenge for any tech company working with high volumes of transactional data. The practical implications of having access to Fast Data are huge for any organization.
3V’s of Data
- Volume. Big Data emphasizes the volume of data
- Velocity. Fast Data emphasizes the velocity of data. Modern enterprise needs to make data-based decisions in real time
- Variety. Smart data emphasizes the variety of data. Enterprise needs a wide variety of data for making decisions suitable for the context.
While some large enterprises have made efforts to build data warehouses, most organizations still leave the majority of their unstructured data unused. The key big data adoption inhibitor is a knowledge gap. Many companies don’t have an understanding of how to create business value based on fast-data systems and many don’t have the skills to build this type of system.
Data Analysis Before, After and During
Data can be used to analyze past, current and future.
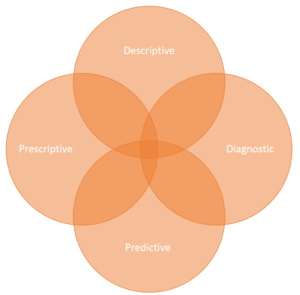
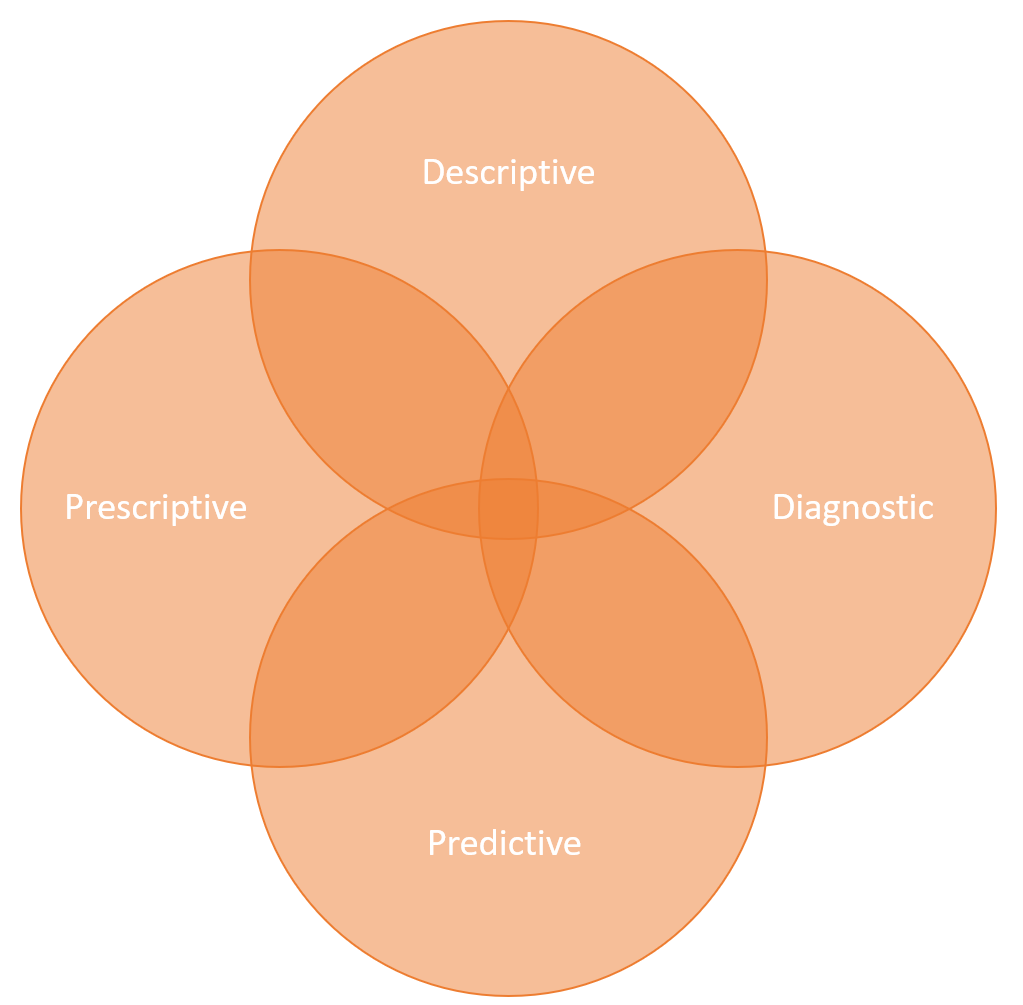
Analytic options can be categorized into high-level buckets, which complement each other:
- Descriptive Analytics: Insight into the past. Uses data aggregation and data mining to provide insight into the past and answer: “What has happened?”. Reports for historical insights.
- Diagnostic Analytics: Similarly to descriptive analytics but with an aim to drill down to isolate all confounding information: “Why did it happen?”. Root cause analysis.
- Predictive Analytics: Understanding the future. Uses statistical models and forecasts techniques to understand the future and answer: “What could happen?”. Forecasting of demand and output.
- Prescriptive Analytics: Advice on possible outcomes. Uses optimization and simulation algorithms for advice: “What should we do?”
No matter, what the business is about, data-analytics can be used to understand the past, predict the future and even to suggest the best possible ways forward.
Tech Stack
A modern fast data architecture is based on four cornerstones.
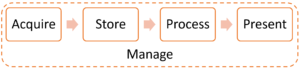
- Acquisition: Fast and reliable data acquisition, where data enters the system from numerous sources. The focus must be on performance and dealing with back pressure, where data is generated faster than it is consumed. From a technology perspective, this means using streaming APIs and messaging solutions like Apache Kafka, Akka Streams, Amazon Kinesis, Oracle Tuxedo or ActiveMQ/ RabbitMQ/ SoniqMQ/ JBossAMQ
- Storage: Flexible storage and querying, where both logical and physical data storage is taken into consideration. There is no single good answer on how to model the data. Textual data falls into RDBM, but not all data is text. The main driver for the increase in the volume of data is the growth of unstructured/non-text data due to the increased availability of storage and the number of complex data sources. Unstructured data currently forms up to 80% of enterprise data. While the unstructured data has no identifiable internal structure, the data models must be based on solving the use cases will be created through experiments. E.g. Redis and Cassandra are one option for running fast-data, where the speed of a Redis combined with the performance of Cassandra makes working with data fast and easy. From a technology standpoint, we are using Apache Cassandra, Apache Hive, Amazon DynamoDB, Couchbase, Redis, MemSQL, MariaDB/MongoDB.
- Processing: Sophisticated processing and analysis are nowadays usually implemented as a hybrid between traditional batch processing and modern stream processing. Traditional ETL processes are run as batches and real-time online processes as streams. The same goes with the location of processing; It is common practice to combine in-memory and on-disk processing to reach the optimal results. In-memory processing can be accomplished via traditional databases or via NoSQL data grids. Data proximity discusses whether data is available locally. The best performance is reached when processing local data. Data locality is the idea of moving computation to the data rather than data to the computation and data gravity mean considering the overall cost associated with data transfer. From the technology aspect, we have solutions like Apache Spark/Flink/Storm/Beam and Tensorflow.
- Presentation: Presentation combines technology, science, and art. Presentations can be divided, for example, into notebooks, charts, maps and graphics. Common technologies here are Apache Zeppelin, Jupyter, Tableau, D3.js and Gephi.
Moreover, you need a fast data infrastructure with an affordable total cost of ownership. Common management technologies are AWS, Docker, Kubernetes, Spinnaker and Apache Mesos
Examples
| Big Data | Fast Data |
| Automakers improve the efficiency and safety of cars using data-analysis during car design | Automakers improve the efficiency and safety of cars using connected, autonomous cars to optimize the route and speed based on location, traffic and predictive maintenance information |
| Health care system suggests for a diagnose based on a historical dataset | Health care system predicts a heart attack based on real-time data |
| Warehouse determines what products to order based on analysis of the previous quarter | The online store offers personalized recommendations real-time based on customer behaviour |
| Credit card company creates risk models based on demographic data | Credit card company reacts real-time on potential credit fraud |
| Aeroplane manufacturer improves the maintenance plan of aeroplane based on data-analysis of historical data | Aeroplane manufacturer suggests maintenance activities real-time regarding technical status, location, routes and coming time tables of the plane |
| Cargo companies optimize parcel routes based on historical data | Cargo companies optimize ship and truck routes real-time based on weather, traffic and content of the vessel |
| Telecom operator adjusts the base-station location and configurations based on earlier collected data. | Telcom operator combines fast data and 5G network slicing to split a single physical network into multiple virtual networks and apply different policies to each slice to offer optimal support for different types of services and real-time charging based on usage. |
You may also be interested in these posts:
Digital transformation calls for agile strategy and culture change
5G changes everything
A developers perspective