
What is nushell?
Nushell is a command line shell, like sh, bash, zsh, or fish. Its purpose is to provide a text interface to an operating system.
It differs from most other shells by working on typed data. This means strongly typed, structured data like integers, strings, records and tables. In this sense it’s more like a scripting language, but has ready types for common operating system concepts like file size, dates and durations. This allows for less ambiguity in places like function arguments, where you don’t need to guess what format you need to provide the date in, since it’s a date type you should provide.
What makes nushell great to use is its standard library of functions for handling data. There are tons of useful generic bits of functionality you can use in pipelines to handle tasks. These are usually delegated to separate programs per the Unix philosophy, but with structured data they really make sense to build into the shell itself.
More generally, nushell mostly ignores common Unix philosophy interpretations in favor of being the most useful shell for the tasks it is designed for it can. This comes with upsides and downsides.
It is also important to note, that nushell is not sh-compatible, so it cannot be used to run bash scripts or utilize other sh-related things like environment files.
But I don’t want to switch to another shell!
Me neither! Even though nushell’s default configuration does a lot right, for example visually searchable command history, I am not and would not recommend using it as your primary shell. I tried and went back to zsh. This is mostly due to its still-changing syntax causing sudden breakage on update and the aforementioned sh-incompatibility causing issues with existing tooling.
But despite going back to zsh, I couldn’t forget about the great data handling experience, so I started using it as a shell scripting tool instead.
Okay so what can I do with it?
I currently use nushell for three things it is better at than any other shell I’ve tried: ad-hoc data handling, making command line tools and task-specific command line environments.
Data handling
Generally there are four ways of doing ad-hoc command line data handling:
- Commonly available CLI tools (like cat, grep, cut, curl…)
- Newer variants of such tools (like httpie, ripgrep, bat, jq, qsv)
- Scripting language runtimes (like python, nodejs or perl) and their libraries (like pandas or polars)
- Ad-hoc databases like sqlite
The first one is great since it usually doesn’t require many new installed packages. You can usually rely on most of those tools being available on Unix-like platforms.
The second one improves upon the first in usability and features at the cost of requiring installing specialized tools. These tools usually have nicer usability and a more modern user experience that supports common use cases better. See for example curl vs. httpie.
The third provides a rich system of structured types and generally better abstractions than pure shell environments, but invoking external tools is often clunky. Great for self-contained operations or where ready libraries exist to accomplish given tasks.
The fourth is useful for complex data queries. Basically you use one of the first three to dump all your data into a temporary database, then do your data processing and queries there and export the result.
Nushell provides a fifth option that combines most of the advantages from each of them. It’s a single dependency to install and available to most platforms. Its tools provide a modern, usable interface and user experience out of the box. It has a type system and related abstractions. Finally, it has a good query language for expressing quite complex operations. If you really need more complex operations it has a dataframe extension ready.
Focusing all this related functionality into this one tool for data handling while supporting utilizing external programs and having it all be cross-platform is a really powerful combination.
Sample
To demonstrate handling data with nushell, let’s get some data from a REST API and do some operations on it. I’ll use screenshots to show how working with nushell looks like with zero customizations.
I’m going to use jsonplaceholder.typicode.com‘s API to find all users who have both posts and photo albums with titles containing the word “minima” and save that to a CSV file.
First, let’s get a sample of the post list:
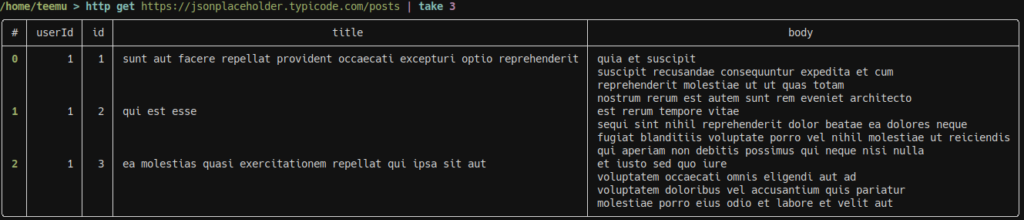
Okay, so we filter by title and save the result to a variable.
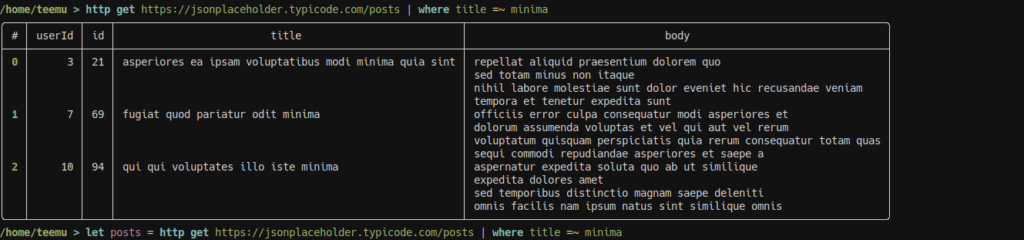
Next we want to find all photo albums by users who made the posts. First, let’s see how to photo album API looks like:

Clear enough, now we need to get these for each user, so let’s get the userIds from our saved posts and fetch them in parallel:

Oh, right, each fetch returns a table so we get a list of tables. The columns are the same though so we can just flatten them into one table and filter the results by title:

Now that we have both posts and albums, we need to figure out the cases where a user has both a post and an album with the desired title. We can use join to combine our two tables. We don’t want all the columns from both, so let’s filter them down to userIds to use for joining and titles to verify our result.

Oh, seems there’s actually only one such user. That title_ is ugly though, let’s rename the columns before exporting the CSV.

And there we have it! As you can see, opening the CSV with nushell’s open gets us the same structure back and the file contents look like they should. Making a JSON, TOML, YAML etc is just a matter of changing the to csv correspondingly.
Shell scripts
Previously my script evolution would go like this:
- I did a thing on the command line
- Later, I search for how I did that thing a few times to do it again
- I decide to put it in a bash script
- After one or two uses I add some parameters
- The parametrization and/or script becomes complex
- I rewrite the script in Python
The thing that changes over those steps is the complexity of the script itself. Simple scripts are easier to do in Bash, but complex scripts are easier to do in Python. Neither makes expressing a nice command line interface easy.
Nushell fixes this by being great for both simple and complex scripts, and by providing a great system for expressing command line interfaces.
The simplest nushell script is just the commands you want to run, just like with bash. However, nushell’s types, abstractions (like structured types, typed functions and lambdas) and standard libary of functions allow for
expressing more complex operations as well. I’m not sure if it allows for a much complexity as Python, for example, but a whole lot more than Bash.
Making a user friendly command line interface for a nushell script is as simple as defining a main function. This gives you arguments, flags, options, default values, subcommands and help texts to name a few. All the data provided to your main function is also type checked, so you can just expect an integer or a date and be sure you got one. If the user provides something else they get a nice error message explaining this.
Sample
Now let’s turn our data handling expressions into a parametrized script. First, we’ll just wrap the code into a main function:
#!/usr/bin/env nu
def main [] {
let posts = http get https://jsonplaceholder.typicode.com | where title =~ minima;
let albums = $posts
| get userId
| par-each {|| http get $'https://jsonplaceholder.typicode.com/user/($in)/albums' }
| flatten
| where title =~ minima;
let result = $posts
| select userId title
| join ($albums | select userId title) userId
| rename userId post_title album_title;
$result | to csv
}Next we should probably make that endpoint into a constant and parametrize the title query. We should probably default to the “minima” we used last time, since that’s our main use case:
#!/usr/bin/env nu
const endpoint = 'https://jsonplaceholder.typicode.com';
def main [query: string = 'minima'] {
let posts = http get $'($endpoint)/posts' | where title =~ $query;
let albums = $posts
| get userId
| par-each {|| http get $'($endpoint)/user/($in)/albums' }
| flatten
| where title =~ $query;
let result = $posts
| select userId title
| join ($albums | select userId title) userId
| rename userId post_title album_title;
$result | to csv
}We needed to save a CSV for our initial use case, but that would probably work better as an option. We could just return the result, but that would work nicely only within nushell and we want this to also be executable more generally to produce CSVs. So let’s add an option for output format.
#!/usr/bin/env nu
const endpoint = 'https://jsonplaceholder.typicode.com';
def main [query: string = 'minima', --format (-f): string] {
let posts = http get $'($endpoint)/posts' | where title =~ $query;
let albums = $posts
| get userId
| par-each {|| http get $'($endpoint)/user/($in)/albums' }
| flatten
| where title =~ $query;
let result = $posts
| select userId title
| join ($albums | select userId title) userId
| rename userId post_title album_title;
$result | match $format {
'csv' => { to csv },
'json' => { to json },
'yaml' => { to yaml },
_ => { $in }
}
}That’s better. The option has both a long and short formats and selects a suitable conversion based on the value. If no valid format was given, the function just returns the pretty printed nushell value.
Finally, let’s add a subcommand. We may want to get just the posts at some point, so let’s do that. We’ll also make put the formatting part into a function so we can reuse it.
#!/usr/bin/env nu
const endpoint = 'https://jsonplaceholder.typicode.com';
def apply_format [format: string] {
match $format {
'csv' => { to csv },
'json' => { to json },
'yaml' => { to yaml },
_ => { $in }
}
}
def main [query: string = 'minima', --format (-f): string] {
let posts = http get $'($endpoint)/posts' | where title =~ $query;
let albums = $posts
| get userId
| par-each {|| http get $'($endpoint)/user/($in)/albums' }
| flatten
| where title =~ $query;
let result = $posts
| select userId title
| join ($albums | select userId title) userId
| rename userId post_title album_title;
$result | apply_format $format
}
def 'main posts' [query: string = 'minima', --format (-f): string] {
http get $'($endpoint)/posts'
| where title =~ $query
| apply_format $format
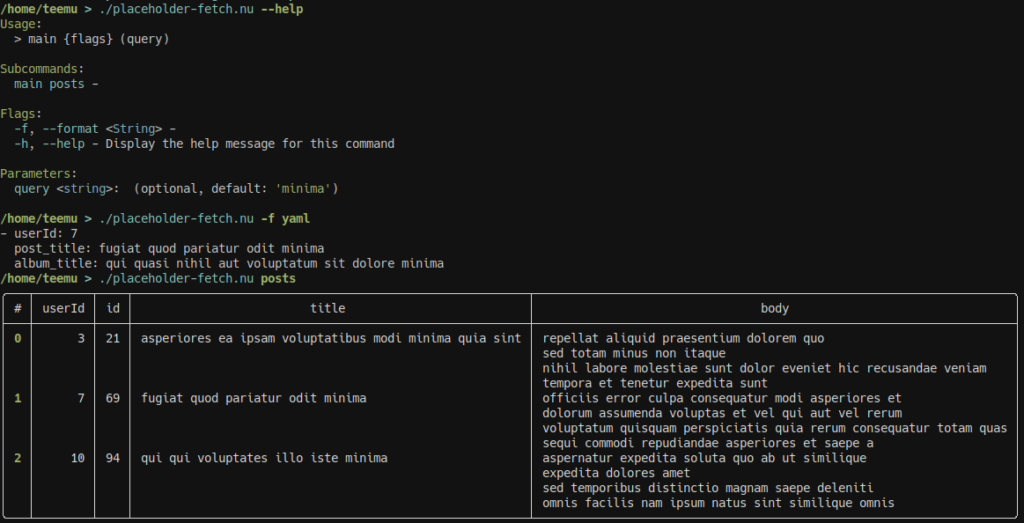
}Here’s the script in action:
Task specific environments
Of the three this is my most rarely used one, but it’s great when it fits. You can do this in other shells with a sourced bash file or a REPL-imported script in something like ipython, but for the same reasons as above it’s not quite as ergonomic as with nushell.
Here you define a nushell script that doesn’t actually run anything. It sets some environment variables like API keys and file paths, then defines a bunch of ready operations for some task and exports them. A common case I have for this is fetching stuff from a REST API and doing common things to it based on transient needs. This is a lot nicer if you don’t need to clutter every command with endpoint addresses, headers, boilerplate processing and irrelevant command names. It lets you focus on the task instead of the tools.
Nushell has a concept called overlays for this very purpose. You can activate an overlay that provides some resources and when you’re done with the task you drop the overlay and all the tools go away from polluting your shell environment.
Sample
To demonstrate overlays we’ll extract the REST API calls from the previous example into an overlay. We’ll then see how it can be utilized on the command line and finally employ the overlay in our script and .
First, here’s the overlay file.
export-env {
$env.ENDPOINT = 'https://jsonplaceholder.typicode.com'
}
export def fetch [path: string] {
http get $'($env.ENDPOINT)($path)'
}
export def posts [] {
fetch '/posts'
}
export def albums [userId: int] {
fetch $'/user/($userId)/albums'
}Next we’ll import the overlay with use and use some of its functions. Notice how they are namespaced behind the overlay name, so you can use common function names.
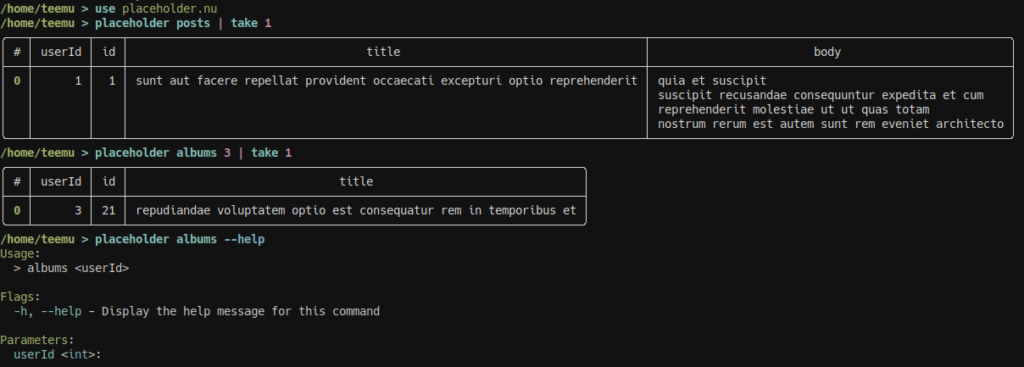
Finally, let’s modify our script to use it as well:
#!/usr/bin/env nu
use placeholder.nu
def apply_format [format: string] {
match $format {
'csv' => { to csv },
'json' => { to json },
'yaml' => { to yaml },
_ => { $in }
}
}
def main [query: string = 'minima', --format (-f): string] {
let posts = placeholder posts | where title =~ $query;
let albums = $posts
| get userId
| par-each {|| placeholder albums $in }
| flatten
| where title =~ $query;
let result = $posts
| select userId title
| join ($albums | select userId title) userId
| rename userId post_title album_title;
$result | apply_format $format
}
def 'main posts' [query: string = 'minima', --format (-f): string] {
placeholder posts | where title =~ $query | apply_format $format
}That’s a lot nicer! Encapsulating interfaces and environments into overlays makes the actual business logic easier to read by hiding the technical details. It also provides a layer verification because of type checking. Let’s see what happens if we try to fetch the albums for an invalid user ID:
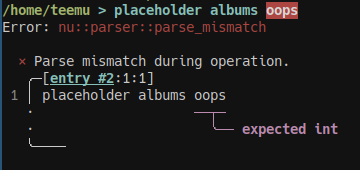
Nushell actually showed that error before I even pressed enter. Because of the typed inteface, it knows there should be an integer there even before I run the code!
Conclusion
Nushell is still in active development and things may still break. It probably won’t replace your favored shell as a daily driver any time soon, though depending on your needs it just as well might.
Nevertheless, it is already a great addition to an active command line user’s toolbox by providing a rich and usable environment for working with data and command line tools. On top of that, it’s a single cross-platform thing to install, which makes it easy to have scripts in your project everyone can utilize, no matter if they run Windows, OS X or Linux.
Head to Nushell Book to learn more!


