

When it comes to developing the actual product, software developers have been adopting practices and tools that speed up the development cycle and simultaneously increase the overall quality of the service you’re running. These practices include things like test automation, collaboration, pair working, short feedback cycles, peer reviewing, modularisation, adoption of functional programming practices and continuous integration/deployment. You should integrate these practices into the development of infrastructure automation too.
As always, it depends on the context which tools and methods one should use, but I’ll make some suggestions as to how you might be able to improve your infrastructure development. The suggestions might sound too obvious, but for some reason, infrastructure development has been treated as a second-class citizen and a lot of the obvious improvements have been neglected. The purpose of improving your infrastructure automation development process is, in the end, to reduce inefficiencies and improve the reliability and speed of deployment.
Explicitly Reserve Time and Resources for Infrastructure Development
 Developing infrastructure automation takes time and resources, but it is often treated as a side activity that doesn’t need allocation of resources. In our experience the workload of infrastructure/ops work and its automation takes roughly 1/5th – 1/10th of the resources compared to the development of the actual product or service in a typical server-driven environment. This is of course highly context dependent and the above shouldn’t be used as a strict guideline. But going way beyond this range might indicate misallocation of resources. And, at the very least, you shouldn’t feel guilty if you’re spending that much time for infrastructure/ops automation. It does take time.
Developing infrastructure automation takes time and resources, but it is often treated as a side activity that doesn’t need allocation of resources. In our experience the workload of infrastructure/ops work and its automation takes roughly 1/5th – 1/10th of the resources compared to the development of the actual product or service in a typical server-driven environment. This is of course highly context dependent and the above shouldn’t be used as a strict guideline. But going way beyond this range might indicate misallocation of resources. And, at the very least, you shouldn’t feel guilty if you’re spending that much time for infrastructure/ops automation. It does take time.
The question of how to divide the effort to create and maintain infrastructure is a bit complicated. It is true that the DevOps culture tries to close the gap between traditional Dev and Ops roles, but it is rare that the Dev team takes the full responsibility for the infrastructure automation. Also, it seems that there is a tendency inside Dev teams for specific people to specialise to these tasks. I believe that the old strict separation of Dev and Ops activities is clearly inferior, but the type of collaboration model that works in each individual situation depends highly on the circumstances.
Make Your Infrastructure Development Cycle More Like a Product Development Cycle
When you accept that the development of infrastructure automation is similar (at least in some aspects) to any other software development activity, you need to start thinking how to incorporate the practices that have made software development faster, more reliable and more agile to your infrastructure automation development process. No longer should you be making one-line changes whose impact you only see in the production environment when the deployment of your software fails and your production suffers.
The picture below shows the typical arrangement of development activities and too often infrastructure automation is not part of the normal development cycle but is done ad-hoc:
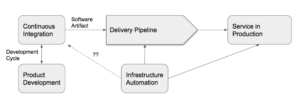
Also, Continuously Integrate Infrastructure Changes
 You probably are already building your software and running test suites for it after each commit. You should do this to your infrastructure automation code too. Preferably in a modular, isolated way. If possible, build tests for your infrastructure automation code too. Like in regular software development, these tests in a unit testing level should be fast and easy-to-run.
You probably are already building your software and running test suites for it after each commit. You should do this to your infrastructure automation code too. Preferably in a modular, isolated way. If possible, build tests for your infrastructure automation code too. Like in regular software development, these tests in a unit testing level should be fast and easy-to-run.
You could argue that if your continuous integration already runs your infrastructure automation when building your actual software then you don’t need to independently check infrastructure automation code. This is true to the extent that you don’t want to make duplicate tests for your code. Optimally exactly one test should fail if you introduce a bug. However, this sort of separation is really difficult to achieve. Furthermore, you should be able to test the infrastructure automation code in a shorter feedback cycle than as a part of some long-running operation that doesn’t clearly indicate the fault.
Run Your Infrastructure Code against Clean Environments
Special attention should be spent to decide how your infrastructure code is tested on clean, pristine environments. One of the big reasons to automate the infrastructure building in the first place was to provide a deterministic and documented way to recreate the whole environment from scratch. But if you don’t regularly do this you will get into a situation where this is no longer possible. Often the changes might work when added incrementally, but not when the whole environment is built from scratch.

The tool support for making virtual environments has taken giant leaps during the last decade, but it is far from a solved problem in my opinion. The speed at which you can set up the whole process and eventually individual virtual environments is still typically too slow. It should be a matter of minutes to set it up and matter of seconds to fire up new environments and run your code on it to make the development cycle comfortable.
The use of containers (Docker and alike) has helped this significantly, but it usually only involves the individual app or component. For any non-trivial software system, you’re going to have at least few containers and the surrounding glue and supporting services like monitoring.
Don’t Forget Documentation
One of the goals of infrastructure automation is to provide documentation of your infrastructure: as program code. This is vastly better than outdated manual documents or worse still some passed-on knowledge that’s only in few people’s heads. But as we know from “self-documenting code” in regular software development this is mostly just a fantasy. Even in the best circumstances, the code only documents the ‘how’ but leaves the ‘why’ unanswered. And the circumstances are not always the best.
This is why I recommend developing practices that encourage documentation of your infrastructure and also the actual automation code too. You will need high-level pictures, design documents, comments and well-designed and well-named infrastructure code. Perhaps one day all of your current team will be replaced by someone else and those quick hacks and strange decisions will make no sense whatsoever.
Think in Modules and Make Things Testable
I feel that there’s a tendency to neglect the practice of modularisation when making infrastructure code. What I mean is that in regular software development we’re careful not to introduce dependencies between functionally separate parts of the code, but with infrastructure automation, we sometimes slip these sorts of unnecessary interlinks between modules. What this often manifests as is a complicated or long procedure to enable testing of a simple component. For an example, it might be that running a single component in your setup first requires setting up multiple other components. Ideally, you should be able to functionally test the infrastructure code for your component without any extra dependencies.
This is of course highly dependent on the architecture of your actual infrastructure and sometimes you cannot avoid these dependencies. But I still think it is an important point to consider when developing the infrastructure and its automation. I find it helps to think in terms of test-driven development even if the actual testing as a unit is unfeasible. If you realise that in order to test a single component you would need to run all your infrastructure code first, you might consider a different approach for your code.
Peer Review for Improved Understanding and Efficiency
 Peer reviewing is an easy and obvious way to improve your infrastructure development. It is too often the case that infrastructure development is left outside peer reviewing and other collaboration methods which further separates it from other development activities and often leaves it to only one or few people’s responsibilities. I’m not saying that each and every developer should contribute equally to all infrastructure development, but with peer reviewing you can spread knowledge and improve the quality of your code without too much effort.
Peer reviewing is an easy and obvious way to improve your infrastructure development. It is too often the case that infrastructure development is left outside peer reviewing and other collaboration methods which further separates it from other development activities and often leaves it to only one or few people’s responsibilities. I’m not saying that each and every developer should contribute equally to all infrastructure development, but with peer reviewing you can spread knowledge and improve the quality of your code without too much effort.
If the reaction to a pull request of a developer who is inexperienced in ops/infra is that he/she cannot understand the change, then you should consider this as a great opportunity to teach the inner workings of your infra and secondly improve the change in a way that it makes it easier to understand. For example, adding comments or documentation of why the change was necessary or just improving the naming of things and so on.
Conclusions
The main lesson is that you should stop considering infrastructure automation as a side activity compared to the regular software development and start doing things that speed up the development and make the end product less error-prone. Improving the development process of infrastructure automation is not just yak-shaving: its purpose is to save you and your customer money. Finding bugs earlier in your development cycle is always a good idea and this applies to infrastructure automation too.


