
In this blog post, I am going to write about the adventure I had that led to setting up an OCR telegram bot for converting Image to text. I made it for Persian speakers and for now, it supports Persian and English languages.

It is called Nevisaar (in Persian “Writable”)
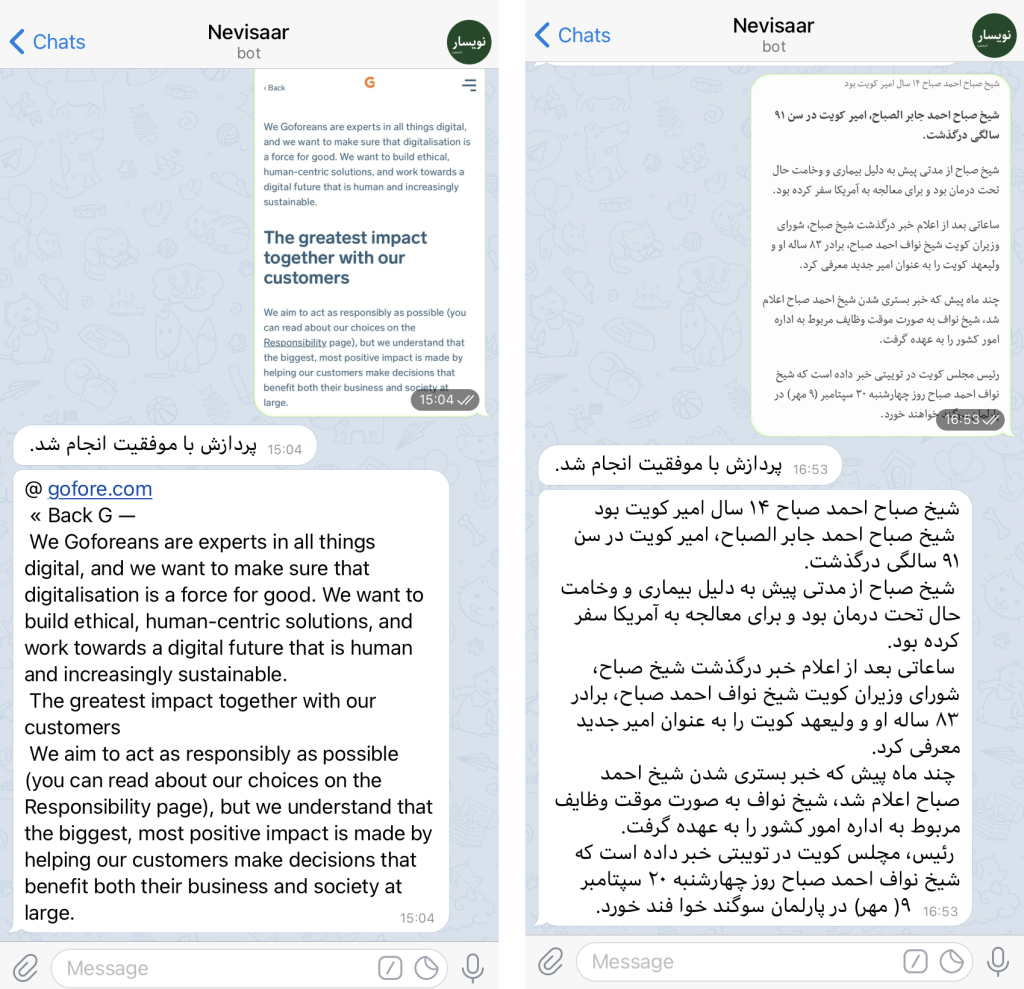
Processed text of an image given to the bot
The idea of an OCR project
I have joined Gofore about a year ago as a researcher to do my PhD. So far, I have been working on my research which is assessing state-of-the-art assistive technologies for the blind and improving the current solutions by finding the research gaps in this area.
For that I needed to deepen my knowledge in computer vision and deep learning. About a month ago, when I was learning about LSTM (Long short-term memory) recurrent neural networks I came across one of the Google projects (Tesseract-ocr) which uses LSTM for OCR (Optical character recognition).
I found the project really interesting since it is open-source and it can be used as a module in the assistive solution that I am working on. So, I decided to dig the repository a little bit and test it with different languages. While testing it, I noticed that this engine has a very good performance on Latin based languages, since the models are trained with 400,000 text lines spanning about 4500 fonts. However, when it comes to some languages that use Arabic script such as Persian (Farsi/Dari), Kurdish, Punjabi, Sindhi, Pashto, or Urdu it doesn’t have very good accuracy.

An example of Persian script (I know, Persian script looks complicated :D)
Challenges & Solutions
I checked the model size and the trained data for the English language was 22.4 MB while the one for the Persian language was 500 KB. I think by just looking at the model size you can estimate the prediction accuracy. :D
Later I found another repo by Google that had some better-trained models. There, I could find another model for the Persian language that was 3.4 MB and had much better accuracy. However, it did not support many fonts and could not recognize some characters like Arabic comma (،).
Since my mother tongue is Persian and I was bored at home because of Madrid’s Corona situation, I decided to work on it as a personal project.
At first, I thought about training my own model but I knew that this needs a powerful machine and even running it on Google Colab won’t help because according to the Tesseract 4.0 documentation, the training from scratch takes a few days to a couple of weeks. But after checking the training documentation, I found out that it is also possible to “Fine Tune” a model. This means taking an already trained model and improve it by adding new fonts and characters to it. THAT WAS GOOD NEWS!
So I decided to find some of the characters and fonts that are used a lot in the Persian language and the model is bad at detecting them. Then I decided to fine-tune the model using ± training for new characters and Fine Tune for Impact for the new fonts. I faced a lot of errors when I first tried to run the training. Due to the inconsistencies in the default training text and the charset of the already trained data, those errors were happening which took me a whole weekend to fix them and prepare a decent dataset for the training (I think this is because those who trained the Persian model did not know the language).
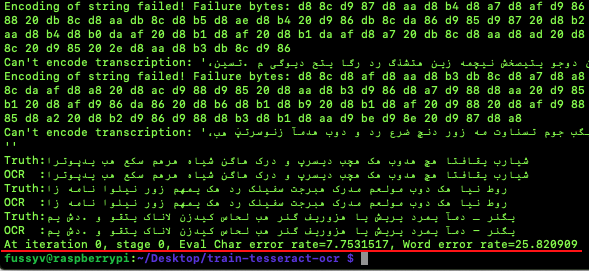 Evaluation results of default model that I got from Github repo (you can see the encoding errors in the evaluation)
Evaluation results of default model that I got from Github repo (you can see the encoding errors in the evaluation)
Interestingly with about 10 (around 9000 words) pages of training text and 3600 iterations I could train the model to detect some characters like (، »« . ّ ) and get better at detecting ”B Nazanin” font which is very popular among Persian speakers. The word error rate decreased from 25% to 5% by only giving some more training text, fixing encoding problems, and adding some missing characters.
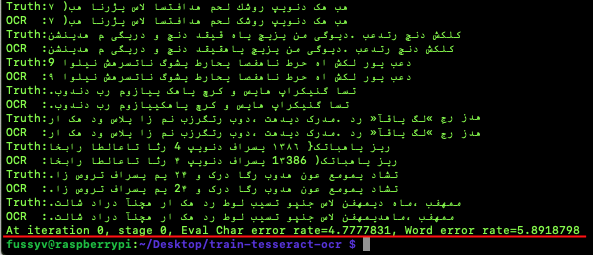 Evaluation results after fine tuning
Evaluation results after fine tuning
The creation of Telegram bot
The error rate is still high in comparison with the English language. I would train a model from scratch if I have the resources one day but even now It has satisfying performance. When I achieved better accuracy, I thought it would be cool if I share it with other Persian speakers and test it with different kinds of texts and get some feedback. Since people mainly use Telegram in Iran and other Persian-speaking countries like Afghanistan, I thought making a Telegram bot would be a good choice.
I searched a little bit on Github and fortunately, someone had already coded a bot that worked with Tesseract. However, the commands and interface of the bot were not user-friendly. I edited the code and made a more interactive interface using Telegram’s Inline Keyboard.
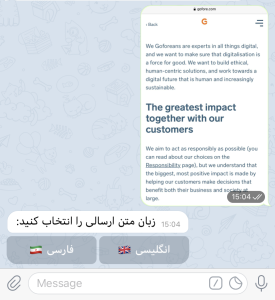
Bot asks user to choose the language of the text used in photo
Now I needed a server to run the project and test it with some users. I already had a Raspberry Pi for testing object recognition algorithms. I thought maybe I can give it a try and see if the Raspberry can handle being an OCR server. Interestingly it did! I set up the bot and shared it on my social media accounts. (I also put a daily limit of 1000 requests so that little raspberry won’t get hurt :D)

I usually keep it open to get some fresh air
People reshared it and I received more than 800 requests on the first day. Now after two weeks I have around 100 images processed per day. It is growing slowly but surely. I have been receiving some feedback from users and noticed that some do not use the bot properly. For example, some users send handwriting images and expect it to work! Or some others send skewed, distorted, and noisy images.
Tesseract automatically undertakes some preprocessing on the image by making it binary or removing noise which sometimes works. But still the preprocessing could be improved by adding deskewing algorithms or removing margins of the image. There are many techniques for doing that and I will improve the bot little by little.
I have received messages from people working in different sectors using the bot. For example, teachers and students found it pretty useful because in our post-COVID life, online learning is getting trendier, and sometimes converting a whole page of a book to the typed format is a cumbersome task and OCR comes in handy.
All in all, I really enjoyed doing this project. If you are interested in giving it a try, you can check it out here. You just need to send a photo for the bot, choose the language of the text, and wait for the result.
Related blog posts:
https://gofore.com/en/how-to-classify-text-in-100-languages-with-a-single-nlp-model/
https://gofore.com/en/artificial-intelligence-is-within-your-reach/
https://gofore.com/en/work-smarter-not-harder-a-chrome-browser-extension-for-development-and-manual-multi-user-testing-at-your-project/
We are always on the lookout for skilled developers to join our crew. Check out our open positions and contact us!


